Knowledge preprocessing stays essential for machine studying success, but real-world datasets usually include errors. Knowledge preprocessing utilizing Cleanlab supplies an environment friendly resolution, leveraging its Python bundle to implement assured studying algorithms. By automating the detection and correction of label errors, Cleanlab simplifies the method of knowledge preprocessing in machine studying. With its use of statistical strategies to determine problematic knowledge factors, Cleanlab permits knowledge preprocessing utilizing Cleanlab Python to boost mannequin reliability. For instance, Cleanlab streamlines workflows, enhancing machine studying outcomes with minimal effort.
Why Knowledge Preprocessing Issues?
Knowledge preprocessing straight impacts mannequin efficiency. Soiled knowledge with incorrect labels, outliers, and inconsistencies results in poor predictions and unreliable insights. Fashions educated on flawed knowledge perpetuate these errors, making a cascading impact of inaccuracies all through your system. High quality preprocessing eliminates these points earlier than modeling begins.
Efficient preprocessing additionally saves time and sources. Cleaner knowledge means fewer mannequin iterations, quicker coaching, and diminished computational prices. It prevents the frustration of debugging complicated fashions when the true downside lies within the knowledge itself. Preprocessing transforms uncooked knowledge into useful info that algorithms can successfully be taught from.
The right way to Preprocess Knowledge Utilizing Cleanlab?
Cleanlab helps clear and validate your knowledge earlier than coaching. It finds dangerous labels, duplicates, and low-quality samples utilizing ML fashions. It’s greatest for label and knowledge high quality checks, not primary textual content cleansing.
Key Options of Cleanlab:
- Detects mislabeled knowledge (noisy labels)
- Flags duplicates and outliers
- Checks for low-quality or inconsistent samples
- Gives label distribution insights
- Works with any ML classifier to enhance knowledge high quality
Now, let’s stroll by way of how you need to use Cleanlab step-by-step.
Step 1: Putting in the Libraries
Earlier than beginning, we have to set up just a few important libraries. These will assist us load the info and run Cleanlab instruments easily.
!pip set up cleanlab
!pip set up pandas
!pip set up numpy- cleanlab: For detecting label and knowledge high quality points.
- pandas: To learn and deal with the CSV knowledge.
- numpy: Helps quick numerical computations utilized by Cleanlab.
Step 2: Loading the Dataset
Now we load the dataset utilizing Pandas to start preprocessing.
import pandas as pd
# Load dataset
df = pd.read_csv("/content material/Tweets.csv")
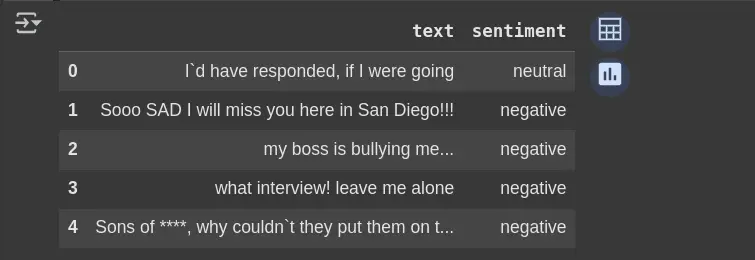
df.head(5)- pd.read_csv():
- df.head(5):

Now, as soon as we’ve got loaded the info. We’ll focus solely on the columns we want and examine for any lacking values.
# Deal with related columns
df_clean = df.drop(columns=['selected_text'], axis=1, errors="ignore")
df_clean.head(5)Removes the selected_text column if it exists; avoids errors if it doesn’t. Helps preserve solely the mandatory columns for evaluation.
Step 3: Verify Label Points
from cleanlab.dataset import health_summary
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.model_selection import cross_val_predict
from sklearn.preprocessing import LabelEncoder
# Put together knowledge
df_clean = df.dropna()
y_clean = df_clean['sentiment'] # Authentic string labels
# Convert string labels to integers
le = LabelEncoder()
y_encoded = le.fit_transform(y_clean)
# Create mannequin pipeline
mannequin = make_pipeline(
TfidfVectorizer(max_features=1000),
LogisticRegression(max_iter=1000)
)
# Get cross-validated predicted possibilities
pred_probs = cross_val_predict(
mannequin,
df_clean['text'],
y_encoded, # Use encoded labels
cv=3,
technique="predict_proba"
)
# Generate well being abstract
report = health_summary(
labels=y_encoded, # Use encoded labels
pred_probs=pred_probs,
verbose=True
)
print("Dataset Abstract:n", report)- df.dropna(): Removes rows with lacking values, making certain clear knowledge for coaching.
- LabelEncoder(): Converts string labels (e.g., “constructive”, “unfavorable”) into integer labels for mannequin compatibility.
- make_pipeline(): Creates a pipeline with a TF-IDF vectorizer (converts textual content to numeric options) and a logistic regression mannequin.
- cross_val_predict(): Performs 3-fold cross-validation and returns predicted possibilities as an alternative of labels.
- health_summary(): Makes use of Cleanlab to investigate the anticipated possibilities and labels, figuring out potential label points like mislabels.
- print(report): Shows the well being abstract report, highlighting any label inconsistencies or errors within the dataset.
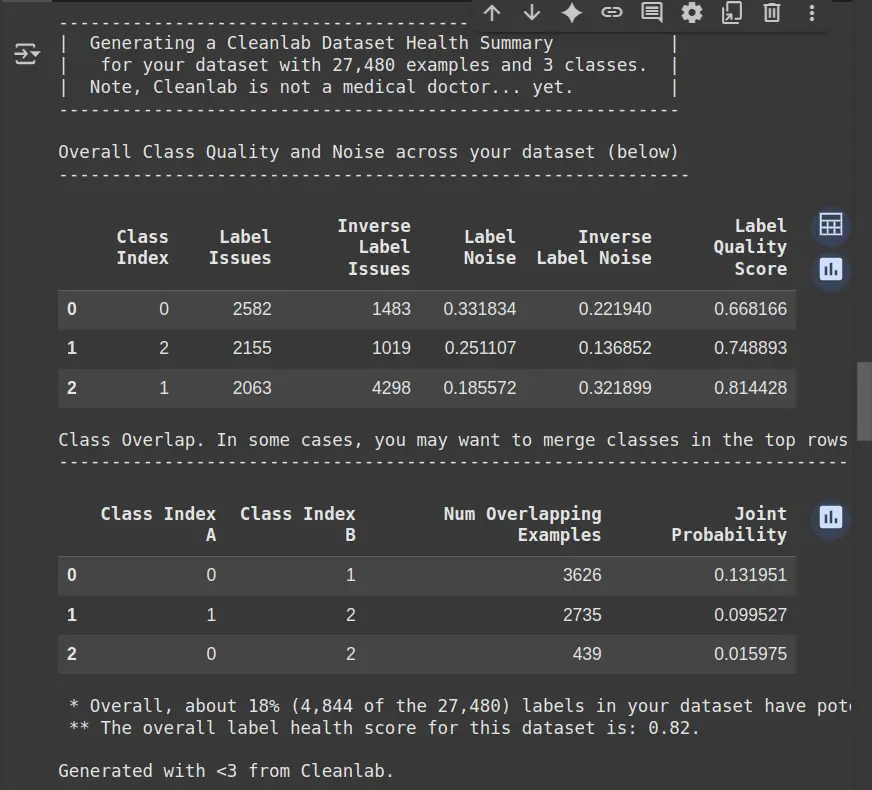
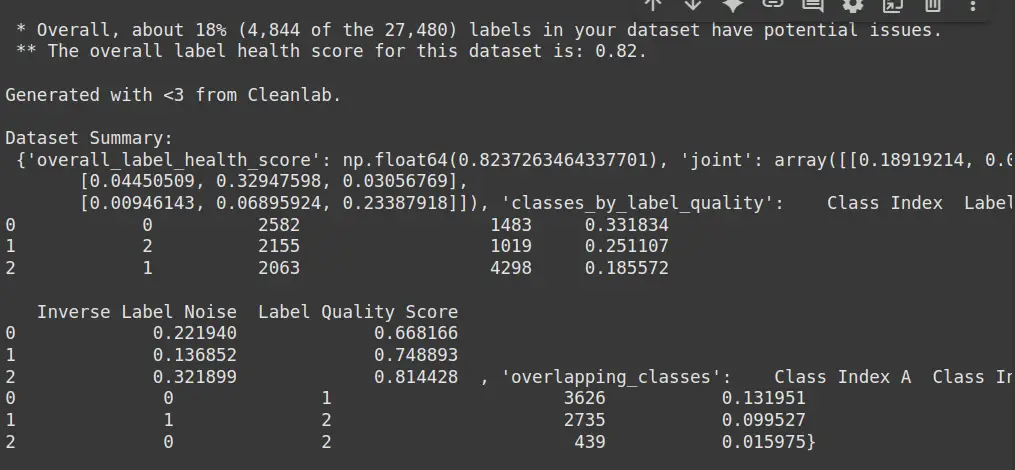
- Label Points: Signifies what number of samples in a category have doubtlessly incorrect or ambiguous labels.
- Inverse Label Points: Exhibits the variety of cases the place the anticipated labels are incorrect (reverse of true labels).
- Label Noise: Measures the extent of noise (mislabeling or uncertainty) inside every class.
- Label High quality Rating: Displays the general high quality of labels in a category (greater rating means higher high quality).
- Class Overlap: Identifies what number of examples overlap between totally different lessons, and the likelihood of such overlaps occurring.
- General Label Well being Rating: Gives an general indication of the dataset’s label high quality (greater rating means higher well being).
Step 4: Detect Low-High quality Samples
This step includes detecting and isolating the samples within the dataset which will have labeling points. Cleanlab makes use of the anticipated possibilities and the true labels to determine low-quality samples, which might then be reviewed and cleaned.
# Get low-quality pattern indices
from cleanlab.filter import find_label_issues
issue_indices = find_label_issues(labels=y_encoded, pred_probs=pred_probs)
# Show problematic samples
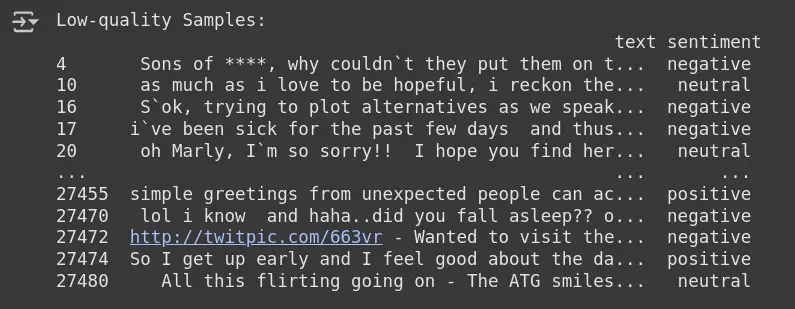
low_quality_samples = df_clean.iloc[issue_indices]
print("Low-quality Samples:n", low_quality_samples)- find_label_issues(): A operate from Cleanlab that detects the indices of samples with label points, primarily based on evaluating the anticipated possibilities (pred_probs) and true labels (y_encoded).
- issue_indices: Shops the indices of the samples that Cleanlab recognized as having potential label points (i.e., low-quality samples).
- df_clean.iloc[issue_indices]: Extracts the problematic rows from the clear dataset (df_clean) utilizing the indices of the low-quality samples.
- low_quality_samples: Holds the samples recognized as having label points, which could be reviewed additional for potential corrections.
Step 5: Detect Noisy Labels through Mannequin Prediction
This step includes utilizing CleanLearning, a Cleanlab technique, to detect noisy labels within the dataset by coaching a mannequin and utilizing its predictions to determine samples with inconsistent or noisy labels.
from cleanlab.classification import CleanLearning
from cleanlab.filter import find_label_issues
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
# Encode labels numerically
le = LabelEncoder()
df_clean['encoded_label'] = le.fit_transform(df_clean['sentiment'])
# Vectorize textual content knowledge
vectorizer = TfidfVectorizer(max_features=3000)
X = vectorizer.fit_transform(df_clean['text']).toarray()
y = df_clean['encoded_label'].values
# Prepare classifier with CleanLearning
clf = LogisticRegression(max_iter=1000)
clean_model = CleanLearning(clf)
clean_model.match(X, y)
# Get prediction possibilities
pred_probs = clean_model.predict_proba(X)
# Discover noisy labels
noisy_label_indices = find_label_issues(labels=y, pred_probs=pred_probs)
# Present noisy label samples
noisy_label_samples = df_clean.iloc[noisy_label_indices]
print("Noisy Labels Detected:n", noisy_label_samples.head())
- Label Encoding (LabelEncoder()): Converts string labels (e.g., “constructive”, “unfavorable”) into numerical values, making them appropriate for machine studying fashions.
- Vectorization (TfidfVectorizer()): Converts textual content knowledge into numerical options utilizing TF-IDF, specializing in the three,000 most vital options from the “textual content” column.
- Prepare Classifier (LogisticRegression()): Makes use of logistic regression because the classifier for coaching the mannequin with the encoded labels and vectorized textual content knowledge.
- CleanLearning (CleanLearning()): Applies CleanLearning to the logistic regression mannequin. This technique refines the mannequin’s capability to deal with noisy labels by contemplating them throughout coaching.
- Prediction Possibilities (predict_proba()): After coaching, the mannequin predicts class possibilities for every pattern, that are used to determine potential noisy labels.
- find_label_issues(): Makes use of the anticipated possibilities and the true labels to detect which samples have noisy labels (i.e., doubtless mislabels).
- Show Noisy Labels: Retrieves and shows the samples with noisy labels primarily based on their indices, permitting you to assessment and doubtlessly clear them.
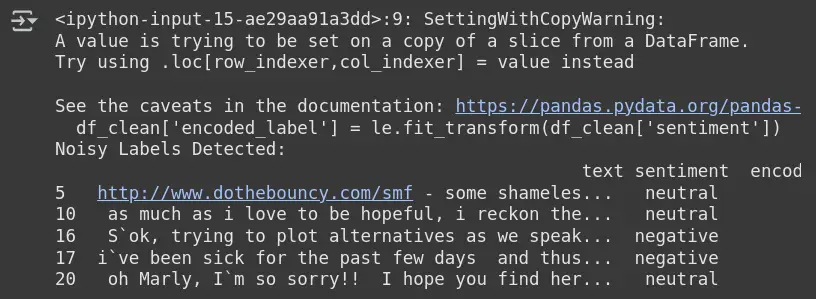
Remark
Output: Noisy Labels Detected
- Cleanlab flags samples the place the anticipated sentiment (from mannequin) doesn’t match the supplied label.
- Instance: Row 5 is labeled impartial, however the mannequin thinks it may not be.
- These samples are doubtless mislabeled or ambiguous primarily based on mannequin behaviour.
- It helps to determine, relabel, or take away problematic samples for higher mannequin efficiency.
Conclusion
Preprocessing is essential to constructing dependable machine studying fashions. It removes inconsistencies, standardises inputs, and improves knowledge high quality. However most workflows miss one factor that’s noisy labels. Cleanlab fills that hole. It detects mislabeled knowledge, outliers, and low-quality samples robotically. No guide checks wanted. This makes your dataset cleaner and your fashions smarter.
Cleanlab preprocessing doesn’t simply increase accuracy, it saves time. By eradicating dangerous labels early, you cut back coaching load. Fewer errors imply quicker convergence. Extra sign, much less noise. Higher fashions, much less effort.
Steadily Requested Questions
Ans. Cleanlab helps detect and repair mislabeled, noisy, or low-quality knowledge in labeled datasets. It’s helpful throughout domains like textual content, picture, and tabular knowledge.
Ans. No. Cleanlab works with the output of current fashions. It doesn’t want retraining to detect label points.
Ans. Not essentially. Cleanlab can be utilized with each conventional ML fashions and deep studying fashions, so long as you present predicted possibilities.
Ans. Sure, Cleanlab is designed for simple integration. You possibly can rapidly begin utilizing it with just some strains of code, with out main adjustments to your workflow.
Ans. Cleanlab can deal with varied sorts of label noise, together with mislabeling, outliers, and unsure labels, making your dataset cleaner and extra dependable for coaching fashions.
Hello, I am Vipin. I am obsessed with knowledge science and machine studying. I’ve expertise in analyzing knowledge, constructing fashions, and fixing real-world issues. I intention to make use of knowledge to create sensible options and continue to learn within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and luxuriate in expert-curated content material.