How do machines uncover probably the most related info from tens of millions of data of huge knowledge? They use embeddings – vectors that symbolize which means from textual content, photos, or audio information. Embeddings enable computer systems to match and in the end perceive extra complicated types of knowledge by giving their relation a measure in mathematical area. However how do we all know that embeddings are resulting in related search outcomes? The reply is optimizing. Optimizing the fashions, curating the info, tuning embeddings, and selecting the right measure of similarity matter lots. This text introduces some easy and efficient strategies for optimizing embeddings to enhance retrieval accuracy.
However earlier than we begin with the right way to optimize embedding, let’s perceive what embedding is and the way retrieval utilizing embedding works.
What are Embeddings?
Embeddings create dense, fixed-size vectors that symbolize info. Knowledge isn’t uncooked textual content or pixels however is mapped into vector area. This mapping preserves semantic relationships, inserting comparable objects shut collectively. From embeddings, new textual content can also be represented in that area. Vectors can then be in contrast with measures like cosine similarity or Euclidean distance. These measures quantify similarity, revealing which means past key phrase matching.
Learn extra: Sensible Information to Phrase Embedding Programs
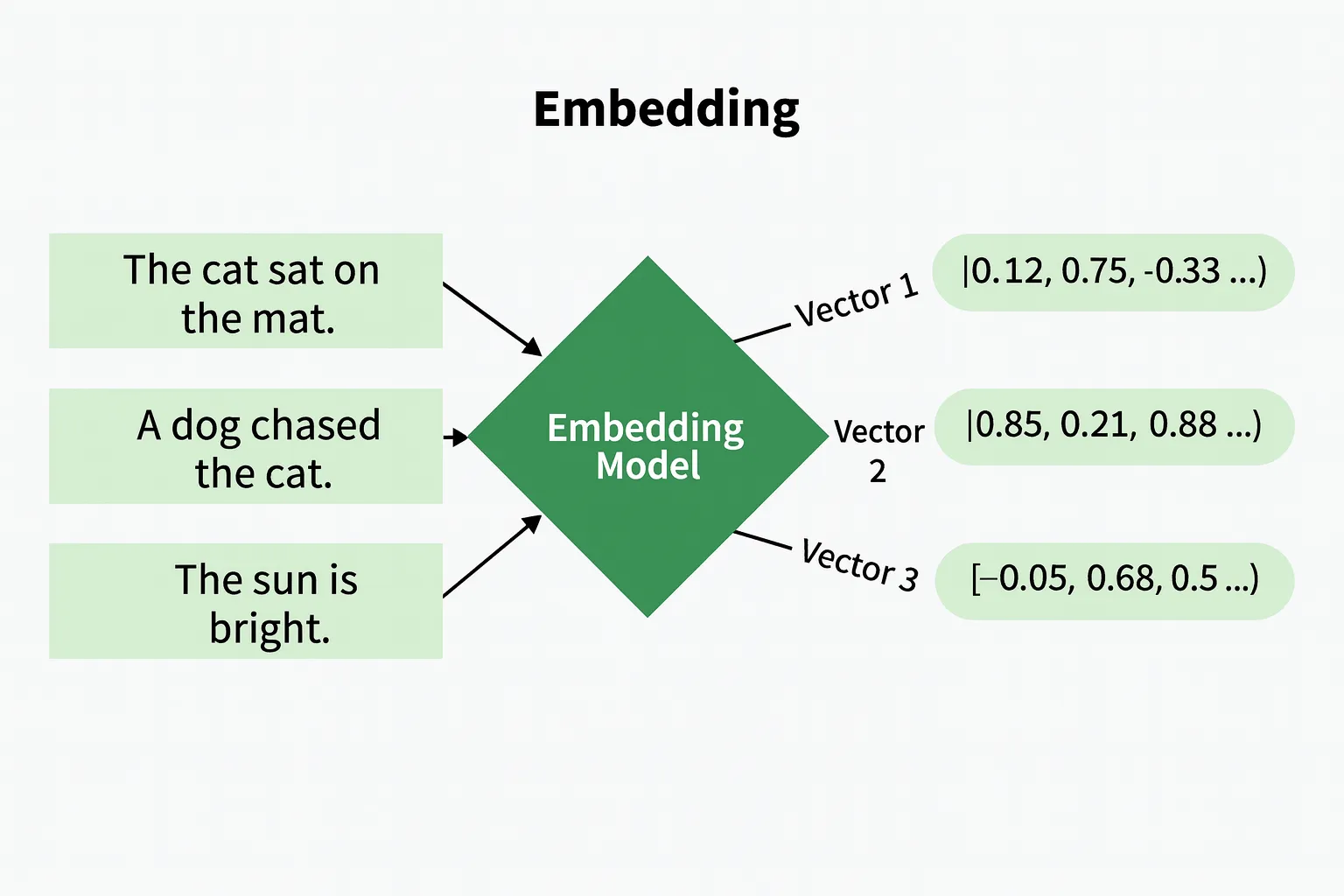
Retrieval Utilizing Embeddings
Embeddings matter in retrieval as a result of each the question and database gadgets are represented as vectors. The system calculates similarity between the question embedding and every candidate merchandise, then ranks candidates by similarity rating. Greater scores imply stronger relevance to the question. That is essential as a result of embeddings let the system discover semantically associated outcomes. They will floor related outcomes even when phrases or options don’t completely match. This versatile method retrieves gadgets primarily based on conceptual similarity, not simply symbolic matches.
Optimizing Embeddings for Higher Retrieval
Optimizing the embeddings is the important thing to enhancing how precisely and effectively the system will discover related outcomes:

Select the Proper Embedding Mannequin
Choosing an embedding mannequin is a crucial first step to be used in retrieving correct outcomes. Embeddings are produced by embedding fashions – these fashions merely take uncooked knowledge and convert it into vectors. Nonetheless, not all embedding fashions are well-suited for each function.
Pretrained vs Customized Fashions
There are pre-trained fashions, that are skilled on giant normal datasets. Pre-trained fashions can typically offer you a very good baseline embedding. An instance of a pre-trained mannequin can be BERT for textual content or ResNet for photos. Examples of pre-trained fashions will present us with time and sources, and, whereas they could be a poor match, they could have a very good match. Customized fashions are ones that you’ve got skilled or fine-tuned in your knowledge. These are most popular fashions and return or compute embeddings which are distinctive to your wants, whether or not they be specific language-related, jargon, or constant patterns associated to your use case, the place the customized fashions might yield higher retrieval distances.
Area-Particular vs Common Fashions
Common fashions work effectively on normal duties however usually don’t seize which means with context that’s essential in domain-specific fields, akin to drugs, regulation, or finance. Area-specific fashions, that are skilled or fine-tuned on related corpora, will seize the refined semantic variations and terminology in these fields, leading to a extra correct set of embeddings for area of interest retrieval duties.
Textual content, Picture, and Multimodal Embeddings
When working along with your knowledge, contemplate fashions optimized to your sort of information. Textual content embeddings (e.g., Sentence-BERT) analyze the semantic which means in language. Picture embeddings are carried out by CNN-based fashions and consider the visible properties or options in photos. Multimodal fashions (e.g., CLIP) align textual content and picture embeddings into a standard area in order that cross-modal retrieval is feasible. Subsequently, choosing an embedding mannequin that carefully aligns along with your knowledge sort shall be obligatory for environment friendly retrieval.
Clear and Put together Your Knowledge
The standard of your enter knowledge has a direct impact on the standard of your embeddings and, thus, retrievals.
- Significance of Excessive-High quality Knowledge: The standard of the enter knowledge is absolutely essential as a result of embedding fashions be taught from the info that they see. Noisy enter knowledge and/or inconsistent knowledge will trigger the embeddings to replicate the noise and inconsistency, which is able to doubtless have an effect on retrieval efficiency.
- Textual content Normalization and Preprocessing: Normalization and preprocessing for textual content may be so simple as eradicating all of the HTML tags and lowercasing the textual content by eradicating all of the particular characters and changing the contractions. Then, easy tokenization and lemmatization strategies make it simpler to cope with the textual content by standardizing your knowledge, lowering vocabulary dimension, and making the embeddings extra constant throughout knowledge.
- Dealing with Noise and Outliers: Outliers or unhealthy knowledge that aren’t related to the supposed retrieval can distort embedding areas. Filtering out any faulty or off-topic knowledge permits the fashions to give attention to related patterns. In circumstances of photos, filtering out damaged photos or unsuitable labels will result in higher high quality of embeddings.
Now, let’s examine retrieval similarity scores from a pattern question to paperwork in two eventualities:
- Utilizing Uncooked, Nosy Paperwork: The textual content on this comprises HTML tags and particular characters.
- Utilizing Cleaned and Normalized Doc: On this, the HTML tags have been cleaned utilizing a easy operate to take away noise and standardize formatting.
import numpy as np
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Instance paperwork (one with noise)
raw_docs = [
"AI is transforming industries. <html> Learn more! </html>",
"Machine learning & AI advances daily!",
"Deep Learning models are amazing!!!",
"Noisy text with #@! special characters & typos!!",
"AI/ML is important in business strategy."
]
# Clear and normalize textual content operate
def clean_text(doc):
import re
# Take away HTML tags
doc = re.sub(r'<.*?>', '', doc)
# Lowercase
doc = doc.decrease()
# Take away particular characters
doc = re.sub(r'[^a-z0-9s]', '', doc)
# Exchange contractions - easy instance
doc = doc.exchange("is not", "isn't")
# Strip further whitespace
doc = re.sub(r's+', ' ', doc).strip()
return doc
# Cleaned paperwork
clean_docs = [clean_text(d) for d in raw_docs]
# Question
query_raw = "AI and machine studying in enterprise"
query_clean = clean_text(query_raw)
# Vectorize uncooked and cleaned docs
vectorizer_raw = TfidfVectorizer().match(raw_docs + [query_raw])
vectors_raw = vectorizer_raw.remodel(raw_docs + [query_raw])
vectorizer_clean = TfidfVectorizer().match(clean_docs + [query_clean])
vectors_clean = vectorizer_clean.remodel(clean_docs + [query_clean])
# Compute similarity for uncooked and clear
sim_raw = cosine_similarity(vectors_raw[-1], vectors_raw[:-1]).flatten()
sim_clean = cosine_similarity(vectors_clean[-1], vectors_clean[:-1]).flatten()
print("Similarity scores with RAW knowledge:")
for doc, rating in zip(raw_docs, sim_raw):
print(f" - {rating:.3f} : {doc}")
print("nSimilarity scores with CLEAN knowledge:")
for doc, rating in zip(clean_docs, sim_clean):
print(f" - {rating:.3f} : {doc}")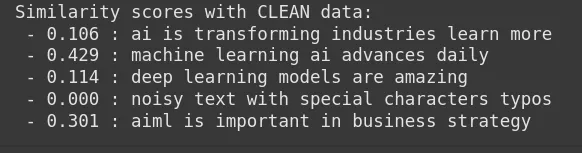
We will see from the output that the similarity rating within the uncooked knowledge is decrease and fewer constant, whereas within the cleaned knowledge, the similarity rating for the related paperwork has improved, displaying how cleansing helps embedding give attention to significant patterns.
Tremendous-Tune Embeddings for Your Particular Job
The pre-trained embeddings may be fine-tuned to raised fit your retrieval activity.
- Supervised Tremendous-Tuning Approaches: Fashions are skilled on labelled pairs (question, related merchandise) or triplets (question, related merchandise, irrelevant merchandise) to maneuver related gadgets nearer collectively within the embedding area, and transfer irrelevant gadgets additional aside within the embedding area. This performance-oriented fine-tuning method is beneficial for enhancing relevance in your retrieval activity.
- Contrastive Studying and Triplet Loss: Contrastive loss goals to place comparable pairs as shut within the embedding area as doable whereas maintaining distance from a dissimilar pair. Triplet loss is a generalized model of this course of the place an anchor, constructive, and unfavorable pattern are used to tune the embedding area to change into extra discriminative to your particular activity.
- Exhausting Damaging Mining: Exhausting unfavorable samples, the place they’re very near constructive samples however irrelevant, push the mannequin to be taught finer distinctions and to extend retrieval accuracy.
- Area Adaptation and Knowledge Augmentation: Tremendous-tuning on activity or domain-specific knowledge consists of particular vocabulary and contexts and has the impact of adjusting the embedding to replicate these viewers contexts. Knowledge augmentation strategies, like paraphrasing, translating merchandise descriptions, and even synthetically creating samples, present one other dimension to coaching knowledge, making it extra strong.
Choose Acceptable Similarity Measures
The measure used to match embeddings tells us how the retrieval candidates rank in similarity.
- Cosine Similarity vs. Euclidean Distance: Cosine similarity represents the angle between vectors and, as such, focuses solely on route, ignoring magnitude. Consequently, it’s typically probably the most incessantly used measure for normalized textual content embeddings, because it precisely measures semantic similarity. Alternatively, Euclidean distance measures straight-line distance in vector area and is beneficial for conditions when the variations in magnitude are related.
- When to Use Discovered Similarity Metrics: Typically, it’s most likely greatest to coach a neural community to be taught similarity features suited to your knowledge and activity. In such circumstances, the discovered metrics will doubtless produce spectacular outcomes. This technique is especially advantageous as discovered metrics will be capable to encapsulate complicated relationships and therefore enhance the retrieval efficiency considerably.
Let’s see a code instance of Cosine Similarity vs Euclidean Distance:
import numpy as np
from sklearn.feature_extraction.textual content import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity, euclidean_distances
# Pattern paperwork
docs = [
"AI transforms the tech industry",
"Machine learning advances AI research",
"Cats are cute animals",
]
# Question
question = "Synthetic intelligence and machine studying"
# Vectorize paperwork and question utilizing TF-IDF
vectorizer = TfidfVectorizer().match(docs + [query])
doc_vectors = vectorizer.remodel(docs)
query_vector = vectorizer.remodel([query])
# Compute Cosine Similarity
cos_sim = cosine_similarity(query_vector, doc_vectors).flatten()
# Compute Euclidean Distance
euc_dist = euclidean_distances(query_vector, doc_vectors).flatten()
# Show outcomes
print("Cosine Similarity Scores:")
for doc, rating in zip(docs, cos_sim):
print(f"Rating: {rating:.3f} | Doc: {doc}")
print("nEuclidean Distance Scores:")
for doc, dist in zip(docs, euc_dist):
print(f"Distance: {dist:.3f} | Doc: {doc}")
From each the outputs, we will see that Cosine similarity tends to be higher in capturing semantic similarity, whereas Euclidean distance may be helpful if absolutely the distinction in magnitude issues.
Handle Embedding Dimensionality
Embeddings are topic to the price of dimension when it comes to efficiency in addition to computational administration.
- Balancing Measurement vs. Efficiency: Bigger embeddings have extra capability for illustration however will take time to retailer, use, and require extra processing. Smaller embeddings require much less time to make use of and scale back complexity, however real-world functions can lose some nuance. Based mostly in your utility’s efficiency and velocity necessities, it’s possible you’ll want to seek out some center floor.
- Dimensionality Discount Methods and Dangers: Strategies like PCA or UMAP can decrease the dimensions of embeddings whereas preserving the construction. However with an excessive amount of discount, it removes a whole lot of semantic meaning-highly degrading retrieval duties. All the time consider results earlier than making use of.
Use Environment friendly Indexing and Search Algorithms
If you’ll want to scale your retrieval to tens of millions or billions of things, environment friendly search algorithms are required.
- ANN (Approximate Nearest Neighbor) Strategies: Precise nearest neighbor search may be expensive to scale. So ANN algorithms give a quick approximate search with little lack of accuracy, which is simpler to work with when working with giant knowledge units.
- FAISS, Annoy, HNSW Overview:
- FAISS (Fb AI Similarity Search) offers high-throughput ANN searches with a GPU, implementing an indexing scheme to allow this.
- Annoy (Approximate Nearest Neighbors Oh Yeah) is light-weight and optimized for read-heavy methods.
- HNSW (Hierarchical Navigable Small World) structured graphs present passable outcomes for recall and search time by traversing layered small-world graphs.
- Commerce-offs Between Velocity and Accuracy: Modify parameters like search depth or variety of probes to handle retrieval velocity and accuracy, primarily based on the precise necessities of any given utility.
Consider and Iterate
Analysis and iteration are essential for repeatedly optimizing retrieval.
- Benchmarking with Commonplace Metrics: Use normal metrics akin to Precision@ok, Recall@ok, and Imply Reciprocal Rank (MRR) to guage the retrieval efficiency quantitatively on validation datasets.
- Error Evaluation: Take into consideration the error circumstances to establish patterns akin to mis-categorisation, regularity, or ambiguous queries. It helps information knowledge clean-up efforts, for tuning a mannequin, or for his or her intent on enhancing coaching.
- Steady Enchancment Methods: Making a plan for steady enchancment that includes person suggestions and knowledge updates alongside studying, there’s new coaching knowledge from scans, retraining fashions with the latest coaching knowledge, and testing fully completely different architectures with hyperparameter variation.
Superior Optimization Methods
There are a number of superior methods to additional enhance retrieval accuracy.
- Contextualized Embeddings: As an alternative of simply embedding single phrases, contemplate using sentence or paragraph embeddings, which replicate a richer which means and context. Discovering fashions that additionally work effectively, akin to Sentence-BERT, will offer you the correct embeddings.
- Ensemble and Hybrid Embeddings: Mix the embeddings from a number of fashions and even knowledge varieties. You would possibly consider mixing textual content and picture embeddings or embedding varied fashions collectively. This can let you retrieve much more info.
- Cross-Encoder Re-ranking: Utilizing embedding retrieval for preliminary candidates, you possibly can take photos returned as candidates and use a cross-encoder to re-rank towards the question by encoding the question and the merchandise as a single joint encoding, or processing the mannequin a number of occasions. It can present a way more exact rating, however with an extended retrieval time.
- Information Distillation: Giant fashions will carry out effectively, however is not going to be quick in retrieving. Upon getting your giant mannequin, distill that information into smaller fashions. Your smaller fashions will let you obtain picture retrieval outcomes simply as earlier than, however shall be a lot quicker and with a really minuscule lack of accuracy. That is nice in manufacturing.
Conclusion
The optimization of embeddings enhances retrieval accuracy and velocity. First, choose the very best accessible coaching mannequin, and comply with with cleansing your knowledge. Subsequent, choose your embeddings and fine-tune them. Then, choose your measures of similarity, and choose the very best search index you possibly can have. There are additionally superior strategies that you would be able to apply to enhance your retrieval, together with contextual embeddings, ensemble approaches, re-ranking, and distillation.
Keep in mind, optimization by no means stops. Maintain testing, studying, and enhancing your system. This ensures your retrieval stays related and efficient over time.
Regularly Requested Questions
A. Embeddings are numerical vectors that symbolize knowledge (i.e., textual content, photos, or audio) in a means that retains semantics. They supply a distance measure to permit machines to match after which shortly discover info that’s related to the embedding. In flip, this improves retrieval.
A. Pretrained embeddings work for many normal duties, and they’re a time saver. Nonetheless, coaching or fine-tuning your embeddings in your knowledge is normally higher and might all the time enhance accuracy, particularly if the subject material is a distinct segment area.
A. Tremendous-tuning means to “alter” a pretrained embedding mannequin. Tremendous-tuning adjusts the mannequin primarily based on a set of task-specific, labeled knowledge. This teaches the mannequin the nuances of that area and improves retrieval relevance.
Hello, I’m Janvi, a passionate knowledge science fanatic at the moment working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we will extract significant insights from complicated datasets.
Login to proceed studying and revel in expert-curated content material.