Multi-Device Orchestration with Retrieval-Augmented Era (RAG) is about creating clever workflows that make use of massive language fashions (LLMs) with instruments, together with internet search engines like google or vector databases, to reply to queries. By doing so, the LLM will mechanically and dynamically choose which instrument to make use of for every question. For instance, the online search instrument will open the area of present up to date info, and the vector database, like Pinecone, for the context-specific info.
In observe, RAG typically entails defining function-call instruments, equivalent to internet search or database lookup, and orchestrating these by way of an API, e.g., the Responses API or OpenAI. This use initiates a sequence of retrieval and technology steps for every person question. Consequently, points of the mannequin’s capability are intertwined with present info.
What are RAGs?
RAG is a course of the place a language mannequin makes use of retrieved related exterior info and incorporates it into its outputs. So, as an alternative of being a “closed-book” mannequin that solely depends on the inner coaching information, a RAG mannequin performs an express retrieval step. It appears to be like by means of a set of paperwork like a vector database or search index and makes use of these retrieved paperwork to reinforce the immediate to the LLM.
With a view to extract information that the LLM attracts upon to supply correct responses to queries. On this means, we will view the method as real-time “augmented” technology. When the LLM is ready to present contextually related, correct solutions to queries by using the technology capabilities and augmented info by means of retrieval on the time of the query. By doing so, it allows the LLM to reply questions with correct, present, domain-specific, or proprietary information it might not have identified at coaching time.
Key benefits of RAG:
- Up-to-date and domain-specific information: RAG permits the mannequin to entry new and non-static coaching information, e.g., present information, inside paperwork, to reply queries.
- Decrease hallucination charge: RAG will decrease hallucinations because the mannequin is answering primarily based on precise retrieved information.
- Verifiability: The reply can cite or show the sources of the retrieved content material, including extra transparency and trustworthiness to the reply.
RAG permits LLMs to bundle generative capability with information retrieval. Within the RAG technique, the mannequin retrieves related snippets of knowledge from exterior corpora earlier than making a solution, after which produces a extra correct and knowledgeable response utilizing that context.
Study extra about what’s RAG in our earlier article.

Instruments like internet search and vector-index queries are essential for RAG as a result of they supply the retrieval part that LLM doesn’t present by itself. When these instruments are added, RAG can remove the problems with counting on LLM companies solely. As an illustration, LLMs have information cutoffs and might confidently produce incorrect or outdated info. A search instrument permits the system to mechanically fetch on-demand information which are updated. Equally, a vector database equivalent to Pinecone shops domain-specific and proprietary information doctor data, firm insurance policies, and so forth., that the mannequin in any other case couldn’t know.
Each instrument has its strengths, and utilizing a mixture of instruments is multi-tool orchestration. As an illustration, the overall web-search instrument can reply high-level questions. A instrument like PineconeSearchDocuments can discover the fitting related entries in an inside vector retailer that incorporates information from a proprietary set of knowledge. Collectively, they make sure that regardless of the mannequin’s reply is, it may be discovered within the supply or wherever it’s best high quality. The overall questions will be dealt with by absolutely functional-built-in instruments equivalent to internet search. “Very particular” questions or medical questions that make the most of information inside to the system are addressed by way of the retrieval of context from a vector database. Total, the usage of multi-tools in RAG pipelines supplies improved validity, correct-to-be information, in addition to accuracy and contemporaneous context.
Now, we’ll undergo a real-world instance of making a multi-tool RAG system utilizing a medical Q&A dataset. The method is, we’ll embed a question-answer dataset into Pinecone and arrange a system. The mannequin has a web-search instrument and a pinecone-based search instrument. Listed below are some steps and code samples from this course of.

Loading Dependencies and Datasets
First, we’ll set up, then import the required libraries, and lastly obtain the dataset. It should require a primary understanding of knowledge dealing with, embeddings, and the Pinecone SDK. For instance:
import os, time, random, string
import pandas as pd
from tqdm.auto import tqdm
from sentence_transformers import SentenceTransformer
from pinecone import Pinecone, ServerlessSpec
import openai
from openai import OpenAI
import kagglehubSubsequent, we’ll obtain and cargo a dataset of medical questions and reply relationships. Within the code, we used the Kagglehub utility to entry a medically targeted QA dataset:
path = kagglehub.dataset_download("thedevastator/comprehensive-medical-q-a-dataset")
DATASET_PATH = path # native path to downloaded information
df = pd.read_csv(f"{DATASET_PATH}/prepare.csv")For this instance model, we will take a subset, i.e., the primary 2500 rows. Subsequent, we’ll prefix the columns with “Query:” and “Reply:” and merge them into one textual content string. This would be the context we’ll embed. We’re making embeddings out of textual content. For instance:
df = df[:2500]
df['Question'] = 'Query: ' + df['Question']
df['Answer'] = ' Reply: ' + df['Answer']
df['merged_text'] = df['Question'] + df['Answer']The merged textual content from rows regarded like: “Query: [medical question] Reply: [the answer]”
Query: Who’s in danger for Lymphocytic Choriomeningitis (LCM)?
Reply: LCMV infections can happen after publicity to recent urine, droppings, saliva, or nesting supplies from contaminated rodents. Transmission might also happen when these supplies are immediately launched into damaged pores and skin, the nostril, the eyes, or the mouth, or presumably, by way of the chunk of an contaminated rodent. Particular person-to-person transmission has not been reported, besides vertical transmission from contaminated mom to fetus, and infrequently, by means of organ transplantation.’
Creating the Pinecone Index Based mostly on the Dataset
Now that the dataset is loaded, we’ll produce the vector embedding for every of the merged QA strings. We are going to use a sentence-transformer mannequin “BAAI/bge-small-en” to encode the texts:
MODEL = SentenceTransformer("BAAI/bge-small-en")
embeddings = MODEL.encode(df['merged_text'].tolist(), show_progress_bar=True)
df['embedding'] = checklist(embeddings)We are going to take the embedding dimensionality from a single pattern ‘len(embeddings[0]’. For our case, it’s 384. We are going to then create a brand new Pinecone index and provides the dimensionality. That is accomplished utilizing the Pinecone Python shopper:
def upsert_to_pinecone(df, embed_dim, mannequin, api_key, area="us-east-1", batch_size=32):
# Initialize Pinecone and create the index if it does not exist
pinecone = Pinecone(api_key=api_key)
spec = ServerlessSpec(cloud="aws", area=area)
index_name="pinecone-index-" + ''.be part of(random.decisions(string.ascii_lowercase + string.digits, okay=10))
if index_name not in pinecone.list_indexes().names():
pinecone.create_index(
index_name=index_name,
dimension=embed_dim,
metric="dotproduct",
spec=spec
)
# Hook up with index
index = pinecone.Index(index_name)
time.sleep(2)
print("Index stats:", index.describe_index_stats())
# Upsert in batches
for i in tqdm(vary(0, len(df), batch_size), desc="Upserting to Pinecone"):
i_end = min(i + batch_size, len(df))
# Put together enter and metadata
lines_batch = df['merged_text'].iloc[i:i_end].tolist()
ids_batch = [str(n) for n in range(i, i_end)]
embeds = mannequin.encode(lines_batch, show_progress_bar=False, convert_to_numpy=True)
meta = [
{
"Question": record.get("Question", ""),
"Answer": record.get("Response", "")
}
for record in df.iloc[i:i_end].to_dict("data")
]
# Upsert to index
vectors = checklist(zip(ids_batch, embeds, meta))
index.upsert(vectors=vectors)
print(f"Upsert full. Index title: {index_name}")
return index_nameThat is what ingests our information into Pinecone; in RAG terminology, that is equal to loading the externally authoritative information right into a vector retailer. As soon as the index has been created, we upsert all the embeddings in batches together with metadata, the unique Query and Reply textual content for retrieval:
index_name = upsert_to_pinecone(
df=df,
embed_dim=384,
mannequin=MODEL,
api_key="your-pinecone-api-key"
)Right here, every vector is being saved with its textual content and metadata. The Pinecone index is now populated with our domain-specific dataset.
Question the Pinecone Index
To make use of the index, we outline a operate that we will name the index with a brand new query. The operate embeds the question textual content and calls index.question to return the top-k most comparable paperwork:
def query_pinecone_index(index, mannequin, query_text):
query_embedding = mannequin.encode(query_text, convert_to_numpy=True).tolist()
res = index.question(vector=query_embedding, top_k=5, include_metadata=True)
print("--- Question Outcomes ---")
for match in res['matches']:
query = match['metadata'].get("Query", 'N/A')
reply = match['metadata'].get("Reply", "N/A")
print(f"{match['score']:.2f}: {query} - {reply}")
return resFor instance, if we have been to name query_pinecone_index(index, MODEL, "What's the commonest therapy for diabetes?"), we’ll see the highest matching Q&A pairs from our dataset printed out. That is the retrieval portion of the method: the person question will get embedded, appears to be like up the index, and returns the closest paperwork (in addition to their metadata). As soon as we now have these contexts retrieved, we will use them to assist formulate the ultimate reply.
Orchestrate Multi-Device Calls
Subsequent, we outline the instruments that the mannequin can use. On this pipeline, we outline two instruments. An online search preview is a general-purpose internet seek for information from the open web. PineconeSearchDocuments for use to carry out a semantic search on our Pinecone index. Every instrument is outlined as a JSON object that incorporates a reputation, description, and anticipated parameters. Right here is an instance:
Step 1: Outline the Net Search Device
The instrument offers the agent the power to carry out an online search just by coming into a pure language request. There’s non-obligatory location metadata, which can improve the specifics of person relevance (e.g., information, companies particular to the area).
web_search_tool = {
"sort": "operate",
"title": "web_search_preview",
"operate": {
"title": "web_search_preview",
"description": "Carry out an online seek for basic queries.",
"parameters": {
"sort": "object",
"properties": {
"question": {
"sort": "string",
"description": "The search question string"
},
"user_location": {
"sort": "object",
"properties": {
"nation": {"sort": "string", "default": "IN"},
"area": {"sort": "string", "default": "Delhi"},
"metropolis": {"sort": "string", "default": "New Delhi"}
}}},
"required": ["query"]
}}
}Due to this fact, it’s used when the agent wants info that’s present or in any other case not contained of their coaching information.
Step 2: Outline the Pinecone Search Device
This instrument allows the agent to conduct a semantic search on a vector database, equivalent to Pinecone, permitting RAG methods to depend on the semantics of the dot product and angle between vectors, for instance.
The instrument takes a question and returns the paperwork which are essentially the most comparable, primarily based on vector embeddings.
pinecone_tool = {
"sort": "operate",
"title": "PineconeSearchDocuments",
"operate": {
"title": "PineconeSearchDocuments",
"description": "Seek for related paperwork primarily based on the person’s query within the vector database.",
"parameters": {
"sort": "object",
"properties": {
"question": {
"sort": "string",
"description": "The query to look within the vector database."
},
"top_k": {
"sort": "integer",
"description": "Variety of prime outcomes to return.",
"default": 3
}
},
"required": ["query"],
"additionalProperties": False
}
}
}That is utilized when the agent must retrieve the context of specificity from paperwork that comprise embedded context.
Step 3: Mix the Instruments
Now we mix each instruments right into a single checklist, which will likely be handed to the agent.
instruments = [web_search_tool, pinecone_tool]So, every instrument features a definition of what arguments our mannequin ought to give it when referred to as. As an illustration, the Pinecone search instrument expects a natural-language question string, and that instrument will return the top-Okay matching paperwork from our index internally.
Together with the instrument, we’ll embody a set of person queries to course of. For every question, the mannequin will decide whether or not it should name a instrument or reply immediately. For instance:
queries = [
{"query": "Who won the cricket world cup in 1983?"},
{"query": "What is the most common cause of death in India?"},
{"query": "A 7-year-old boy with sickle cell disease has knee and hip pain... What is the next step in management according to our internal knowledge base?"}
]Multi-tool orchestration in move
Lastly, we execute the dialog move wherein the mannequin controls the instruments on their behalf. We offer the mannequin a system immediate that directs it to make the most of the instruments in a selected order. On this instance, our immediate tells the mannequin, “When introduced with a query, first name the online search instrument, after which name PineconeSearchDocuments”:
system_prompt = (
"Each time it is prompted with a query, first name the online search instrument for outcomes, "
"then name `PineconeSearchDocuments` to search out related examples within the inside information base."
)We gather the messages and name the Responses API with the instruments enabled for every question from the person:
for merchandise in queries:
input_messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": item["query"]}
]
response = openai.responses.create(
mannequin="gpt-4o-mini",
enter=input_messages,
instruments=instruments,
parallel_tool_calls=True
)Output:
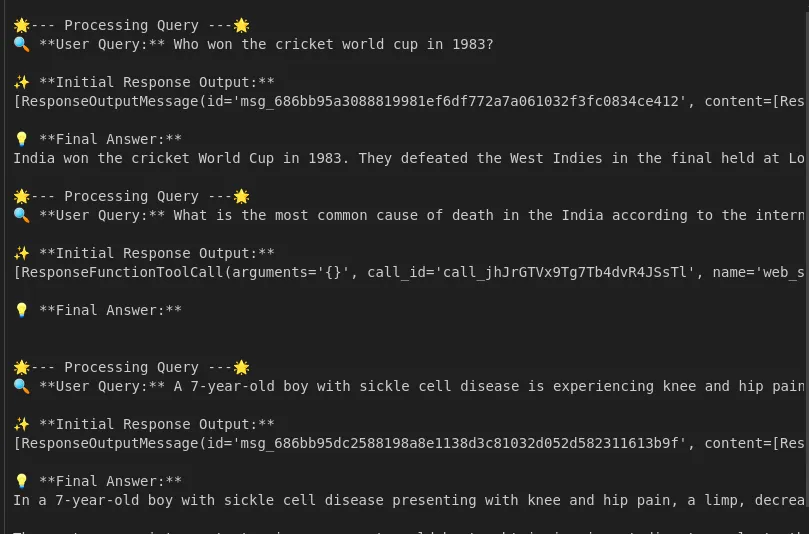
The API returns an assistant message, which can or could not embody instrument calls. We verify response.output to see if the mannequin referred to as any instruments, so if it did, we carry out these calls and embody the ends in the dialog. For instance, if the mannequin referred to as PineconeSearchDocuments, our code runs query_pinecone_index(index, MODEL, question) internally, will get the doc solutions, and returns a instrument response message with this info. Lastly, we ship the refreshed dialog again to the mannequin to get the ultimate response.
The above move exhibits how multi-tool orchestration works; the mannequin dynamically selects instruments concerning the question. As the instance factors out, for basic questions like ‘What’s bronchial asthma?’, it may use the web-search instrument, however questions on extra particular hyperlinks to ‘bronchial asthma’ might want the Pinecone context, on which to construct.
We make a number of instrument calls from our code loop, and in any case have been made, we name the API to permit the mannequin to assemble the ‘remaining’ reply primarily based on the prompts it obtained. Total, we count on to obtain a solution that places collectively each exterior truths from the online information and acknowledges context from the inner information paperwork, primarily based on our directions.
You possibly can consult with the entire code right here.
Conclusion
A multi-tool orchestration with RAG creates a robust QA system with many choices. Utilizing mannequin technology with retrieval instruments permits us to reap the benefits of each the mannequin’s pure language understanding and exterior datasets’ factual accuracy. In our use case, we ground-truthed a Pinecone vector index of medical Q&As wherein we had the potential to name both an online search or that index as choices. By doing this, our mannequin was extra factually grounded in precise information and in a position to reply questions it wouldn’t have the ability to in any other case.
In observe, the sort of RAG pipeline yields higher reply accuracy and relevance because the mannequin can cite up-to-date sources, cowl area of interest information, and decrease hallucination. Future iterations could embody extra superior retrieval schemas or extra instruments throughout the ecosystem, like working with information graphs or APIs, however nothing has to vary throughout the core.
Continuously Requested Questions
A. RAG permits LLMs to entry an exterior information supply like vector databases or the online to generate extra correct, present, and domain-specific responses, which may’t occur with conventional “closed-book” fashions.
A. Sometimes, widespread instruments embody:
– Vector databases like Pinecone, FAISS, or Weaviate for semantic retrieval.
– Websearch utilizing APIs for real-time internet info.
– Customized APIs or capabilities that present querying capabilities of information graphs, SQL databases, or doc storage.
A. Sure. RAG is extremely appropriate for purposes that require dynamic, factual solutions, equivalent to buyer assist bots, medical, or monetary assistants. Because the responses are primarily based on retrievable paperwork or information.
Hey! I am Vipin, a passionate information science and machine studying fanatic with a robust basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My purpose is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my abilities in a collaborative surroundings whereas persevering with to be taught and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.