You’ve most likely heard about Qwen3 Coder, Alibaba’s new AI mannequin that builders are raving about. Now they’ve launched a lighter and quicker verion of the identical mannequin – Qwen3 Coder Flash. What makes it particular? It packs 30.5B parameters however solely makes use of 3.3B at a time by Combination-of-Consultants, making it extremely environment friendly. This instantly addresses what coders want most: a high-performance instrument that received’t overwhelm native setups. With 256K context (expandable to 1M) and strengths in prototyping and API work, it’s constructed for velocity. As open-source software program suitable with platforms like Qwen Code, Flash is completely timed for at this time’s fast-moving AI coding panorama, giving builders the sting to innovate faster. Let’s break down what this implies for sensible use.
Earlier than going forward, I counsel you learn my earlier article on Qwen3 Coder.
What’s Qwen3-Coder-Flash?
Qwen3-Coder-Flash is a specialised language mannequin constructed for writing code. It makes use of a sensible design known as Combination-of-Consultants, or MoE. The mannequin has 30.5 billion parameters, but it surely solely makes use of about 3.3 billion for any single activity. This makes the mannequin very quick and environment friendly.
The title “Flash” highlights its velocity. The mannequin’s structure is optimized for quick and correct code technology. It could possibly deal with a considerable amount of info without delay. The mannequin helps a context of 262,000 tokens. This may be prolonged as much as 1 million tokens for very massive initiatives. This makes it a robust and accessible open-source coding mannequin for builders.
Qwen3-Coder-Flash vs Qwen3-Coder: What’s the Distinction?
The Qwen crew launched two distinct coding fashions. It is very important perceive their variations.
- Qwen3-Coder-Flash (launched as Qwen3-Coder-30B-A3B-Instruct): This mannequin is the agile and quick possibility. It’s smaller and designed to run effectively on customary computer systems with a superb graphics card. It’s preferrred for real-time coding assist.
- Qwen3-Coder (480B): That is the bigger, extra highly effective model. It’s constructed for optimum efficiency on probably the most demanding agentic coding duties. This mannequin requires high-end server {hardware} to function.
Whereas the bigger mannequin scores larger on some checks, Qwen3-Coder-Flash performs exceptionally effectively. It typically matches the scores of a lot bigger fashions. This makes it a sensible alternative for many builders.
Additionally Learn: High 6 LLMs for Coding
Easy methods to Entry Qwen3-Coder-Flash?
Getting began with Qwen3-Coder-Flash is an easy course of. The mannequin is obtainable by a number of channels, making it accessible for fast checks, native growth, and integration into bigger functions. Under are the first methods to entry this highly effective open-source coding mannequin.
1. Official Qwen Chat Interface
The quickest approach to check the mannequin’s capabilities with none set up is thru the official net interface. This offers a easy chat surroundings the place you possibly can instantly work together with the Qwen fashions
Hyperlink: chat.qwen.ai
2. Native Set up with Ollama (Advisable for Builders)
For builders and learners who wish to run the mannequin on their very own machine, Ollama is the best methodology. It permits you to obtain and work together with Qwen3-Coder-Flash instantly out of your terminal, making certain privateness and offline entry.
Easy methods to Set up Qwen3-Coder-Flash Regionally?
You will get this mannequin working in your native machine simply. The instrument Ollama simplifies the method.
Step 1: Set up Ollama
Ollama helps you run massive language fashions by yourself pc. Open a terminal and use the command on your working system. For Linux, the command is:
curl -fsSL https://ollama.com/set up.sh | shInstallers for macOS and Home windows can be found on the Ollama web site.
Step 2: Examine Your GPU VRAM
This mannequin wants adequate video reminiscence (VRAM). You’ll be able to verify your accessible VRAM with this command:
nvidia-smi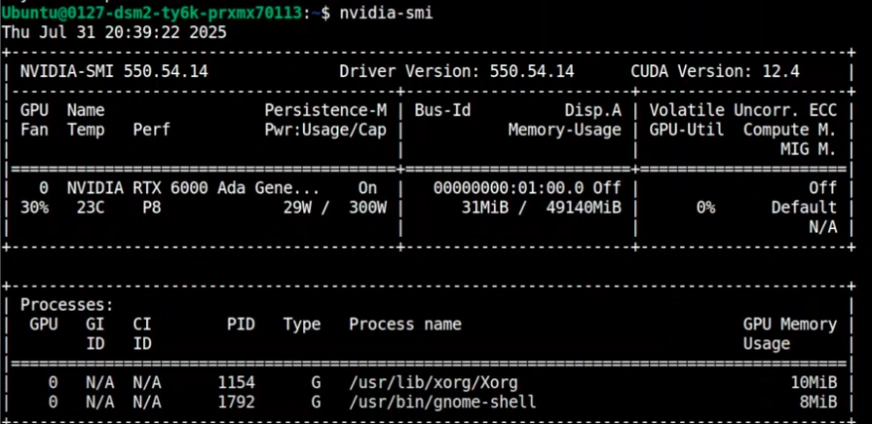
You will want about 17-19 GB of VRAM for the really useful model. When you’ve got much less, you should utilize a model that’s extra compressed.
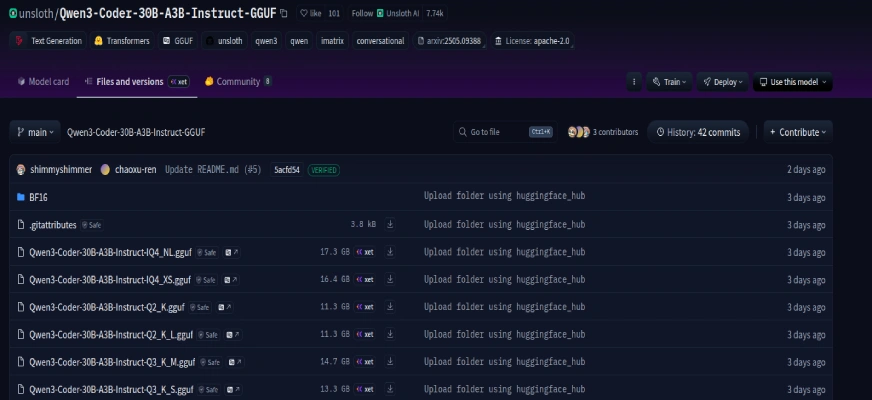
Step 3: Discover the Quantized Mannequin
Quantized variations are smaller and extra environment friendly. Quantization reduces the mannequin’s measurement with little or no loss in efficiency. The Unsloth repository on Hugging Face offers a superb quantized model of Qwen3-Coder-Flash.
You’ll find extra variations right here.
Step 4: Run the Mannequin
With Ollama put in, a single command downloads and begins the mannequin. This command pulls the proper information from Hugging Face.
ollama run hf.co/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF:UD-Q4_K_XL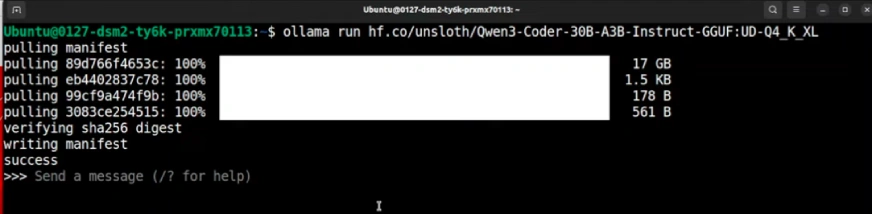
The primary run will obtain the 17 GB mannequin. After that, it’ll launch immediately. This completes the steps to put in Qwen3-Coder-Flash.
Placing Qwen3-Coder-Flash to the Check
Let’s see how the mannequin handles tough duties. The next examples present its spectacular skills
Process 1: Create an Interactive p5.js Animation
A superb check is to request a artistic and visible undertaking. The mannequin was requested to construct a firework present with a rocket.
Immediate: “Create a self-contained HTML file utilizing p5.js that encompasses a colourful, animated rocket zooming dynamically throughout the display in random instructions. The rocket ought to go away behind a path of glowing fireworks that burst into vibrant, radiating particles. The rocket ought to transfer easily, rotate to face its route, and infrequently set off firework explosions. Make the expertise visually participating.”
Output:
Outcome:
The mannequin shortly generated a single HTML file. The animation was easy, visually interesting, and interactive. It completely captured the request for a dynamic space-themed firework present.
Process 2: Optimize a Advanced SQL Question
This activity examined the mannequin’s database information. It was given a poorly written SQL question for a big time-series database.
Immediate: “You’re given a big time-series database ‘sensor_readings’ containing billions of rows from IoT gadgets. The desk schema is as follows: device_id, metric_name, reading_value, reading_timestamp, location_id, standing. Your Process:
1. Rewrite and optimize the offered sluggish question for efficiency on this large-scale dataset (assume 50B+ rows).
2. Recommend new indexes, materialized views, or partitioning methods.
3. Think about using window capabilities, CTEs, or approximate algorithms.
4. Assume the system is PostgreSQL 16 with TimescaleDB allowed.
5. Decrease I/O and cut back nested subquery overhead.
Deliverables: Optimized SQL question, Index ideas, and a abstract of suggestions”.
/* The Sluggish and Inefficient Question */
SELECT
location_id,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY reading_value) AS median_temp,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY reading_value) AS p95_temp
FROM sensor_readings sr1
WHERE
metric_name="temperature"
AND reading_timestamp >= NOW() - INTERVAL '30 days'
AND device_id IN (
SELECT device_id
FROM sensor_readings sr2
WHERE
reading_timestamp >= NOW() - INTERVAL '30 days'
AND metric_name="temperature"
GROUP BY device_id
HAVING AVG(CASE WHEN standing="lively" THEN 1.0 ELSE 0.0 END) >= 0.95
)
GROUP BY location_id;Output:
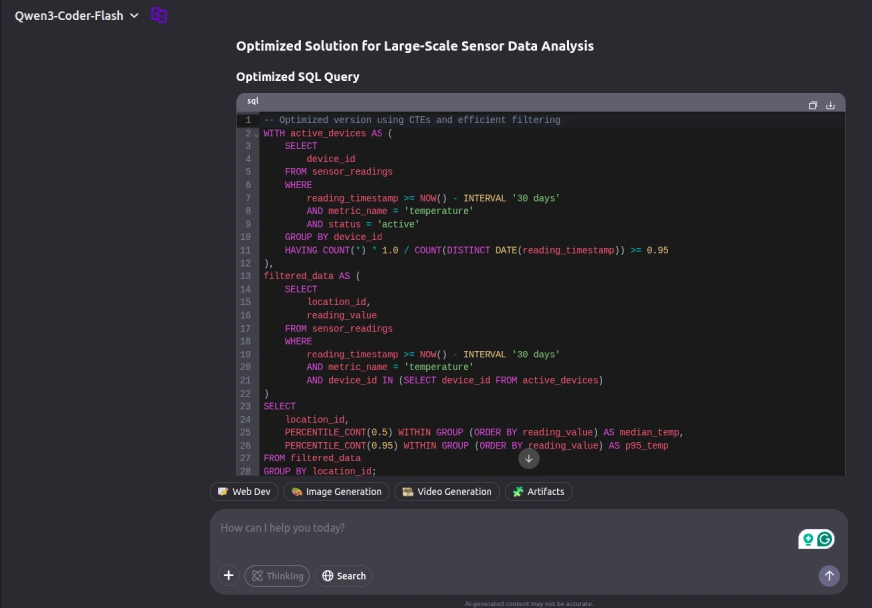
Outcome:
Qwen3-Coder-Flash offered a complete {and professional} resolution, demonstrating deep experience in database optimization. The response featured a transparent question restructuring utilizing Frequent Desk Expressions (CTEs) for improved readability, together with strategic suggestions for composite indexes to boost filtering efficiency. Notably, it additionally included knowledgeable recommendation on implementing time-based partitioning, a important optimization method for dealing with large-scale time-series information effectively. The answer showcased a powerful understanding of superior database efficiency tuning methodologies.
Process 3: Construct a LEGO Builder Sport
This closing activity concerned creating an entire, interactive recreation from an in depth immediate.
Immediate: “Create a self-contained HTML file utilizing p5.js that simulates a playful, interactive LEGO constructing recreation in a 2D surroundings. The sport ought to function a digital workbench the place customers can spawn, drag, rotate, and snap collectively LEGO bricks of varied shapes, sizes, and colours. The core mechanics ought to embody completely different brick varieties, mouse interplay to maneuver bricks, a magnetic snapping system, and stackable bricks.”
Output:
Outcome:
The mannequin produced a practical LEGO sandbox recreation. It created completely different brick varieties and carried out controls for choosing, transferring, and rotating them. The magnetic snapping system labored as described, permitting bricks to attach when shut. The outcome was a enjoyable and interactive constructing recreation, created from a single immediate.
Efficiency Insights and Benchmarks
The benchmark outcomes for Qwen3-Coder-Flash are very sturdy. It holds its personal towards many bigger open-source coding mannequin choices and even some prime proprietary ones.
In checks for agentic coding duties, it achieves scores which are aggressive with fashions like Claude Sonnet-4 and GPT-4.1. That is spectacular for a mannequin of its measurement. It additionally performs effectively in benchmarks that check its potential to make use of an online browser and different instruments. This makes it an important basis for constructing good AI brokers. The Qwen3-Coder vs Flash comparability clearly exhibits that effectivity doesn’t imply a big drop in high quality.
Conclusion
Qwen3-Coder-Flash is a outstanding achievement. It offers a robust and environment friendly instrument for builders. Its stability of velocity and efficiency makes it among the finest decisions for native AI growth at this time. As a result of it’s an open-source coding mannequin, it empowers the group to construct wonderful issues with out excessive prices. The easy course of to put in Qwen3-Coder-Flash means anybody can begin exploring superior AI coding at this time.
Incessantly Requested Questions
A. You want a pc with a contemporary GPU. For the very best expertise, purpose for a graphics card with at the very least 16-20GB of VRAM.
A. Sure, it’s launched below the Apache 2.0 license. This makes it free for each private and business initiatives.
A. Copilot is nice for suggesting strains of code. Qwen3-Coder-Flash can deal with whole initiatives and complicated, multi-step duties like a real AI agent.
A. Sure, whereas it’s best at coding, it is usually a succesful language mannequin. It could possibly assist with writing, summarizing, and different text-based duties.
A quantized mannequin is a compressed model of the unique. This course of makes the mannequin smaller and quicker to run on common {hardware} with little or no affect on its efficiency.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Massive Language Fashions than precise people. Enthusiastic about GenAI, NLP, and making machines smarter (so that they don’t exchange him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.