Language fashions have been quickly evolving on the earth. Now, with Multimodal LLMs taking on the forefront of this Language Fashions race, it is very important perceive how we are able to leverage the capabilities of those Multimodal fashions. From conventional text-based AI-powered chatbots, we’re transitioning over to voice primarily based chatbots. These act as our private assistants, accessible at a second’s discover to are likely to our wants. These days, you’ll find an AI-On this weblog, we’ll construct an Emergency Operator voice-based chatbot. The thought is fairly simple:
- We communicate to the chatbot
- It listens to understands what we’ve mentioned
- It responds with a voice word
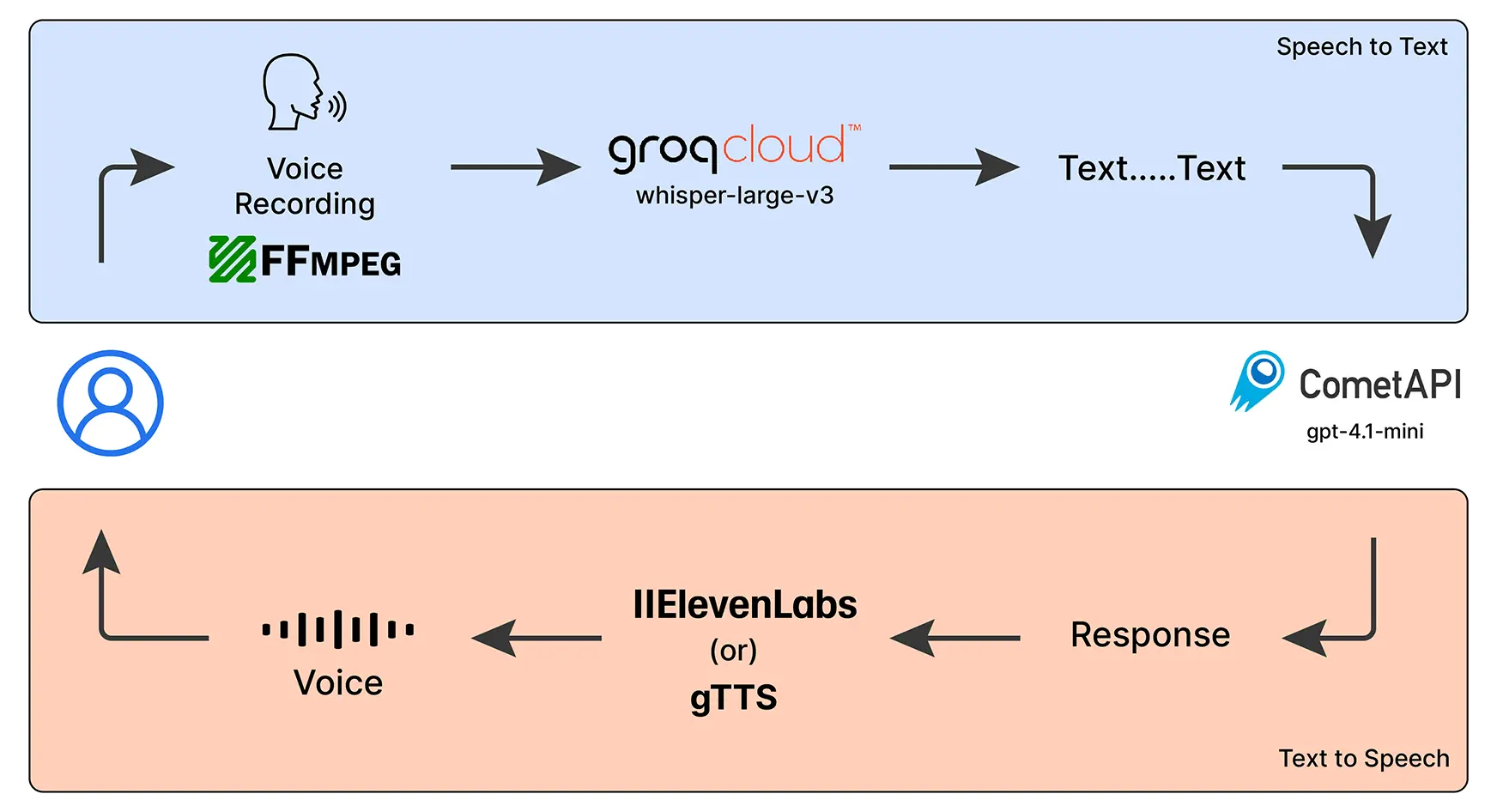
Our Use-Case
Let’s think about a real-world situation. We reside in a rustic with over 1.4 billion folks and with such an enormous inhabitants, emergencies are certain to happen whether or not it’s a medical problem, a fireplace breakout, police intervention, and even psychological well being assist like anti-suicide help and so forth.
In such moments, each second counts. Additionally, contemplating the shortage of Emergency Operators and the overwhelming quantity of points raised. That’s the place a voice-based chatbot could make a giant distinction which may supply fast, spoken help when folks want it essentially the most.
- Emergency Help: Speedy assist for well being, fireplace, crime, or disaster-related queries with out ready for a human operator (when not accessible).
- Psychological Well being Helpline: A voice-based emotional assist assistant guiding customers with compassion.
- Rural Accessibility: Areas with restricted entry to cellular apps can profit from a easy voice interface since folks usually talk by talking in such areas.
That’s precisely what we’re going to construct. We might be appearing as somebody looking for assist, and the chatbot will play the function of an emergency responder, powered by a big language mannequin.
To implement our voice chatbot, we might be utilizing the under talked about AI fashions:
- Whisper (Massive) – OpenAI’s speech-to-text mannequin, working through GroqCloud, to transform voice into textual content.
- GPT-4.1-mini – Powered by CometAPI (Free LLM Supplier), that is the mind of our chatbot that may perceive our queries and can generate significant responses.
- Google Textual content-to-Speech (gTTS) – Converts the chatbot’s responses again into voice so it may possibly discuss to us.
- FFmpeg – A helpful library that helps us document and handle audio simply.
Necessities
Earlier than we begin coding, we have to arrange some issues:
- GroqCloud API Key: Get it from right here: https://console.groq.com/keys
- CometAPI Key
Register and retailer your API key from: https://api.cometapi.com/ - ElevenLabs API Key
Register and retailer your API key from: https://elevenlabs.io/app/residence - FFmpeg Set up
Should you don’t have already got it, observe this information to put in FFmpeg in your system: https://itsfoss.com/ffmpeg/
Verify by typing “ffmeg -version” in your terminal
After getting these arrange, you’re able to dive into constructing your very personal voice-enabled chatbot!
Undertaking Construction
The Undertaking Construction might be moderately easy and rudimentary and most of our working might be taking place within the app.py and utils.py python scripts.
VOICE-CHATBOT/├── venv/ # Digital atmosphere for dependencies
├── .env # Surroundings variables (API keys, and so forth.)
├── app.py # Fundamental software script
├── emergency.png # Emergency-related picture asset
├── README.md # Undertaking documentation (elective)
├── necessities.txt # Python dependencies
├── utils.py # Utility/helper capabilities
There are some needed information to be modified to make sure that all our dependencies are happy:
Within the .env file
GROQ_API_KEY = "<your-groq-api-key"
COMET_API_KEY = "<your-comet-api-key>"
ELEVENLABS_API_KEY = "<your-elevenlabs-api–key"Within the necessities.txt
ffmpeg-python
pydub
pyttsx3
langchain
langchain-community
langchain-core
langchain-groq
langchain_openai
python-dotenv
streamlit==1.37.0
audio-recorder-streamlit
dotenv
elevenlabs
gttsSetting Up the Digital Surroundings
We can even must arrange a digital atmosphere (a superb follow). We might be doing this in terminal.
- Creation of our digital atmosphere
~/Desktop/Emergency-Voice-Chatbot$ conda create -p venv python==3.12 -y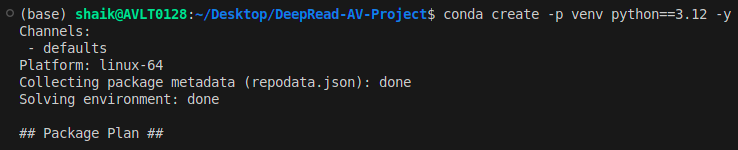
- Activating our Digital Surroundings
~/Desktop/Emergency-Voice-Chatbot$ conda activate venv/
- After you end working the applying, you’ll be able to deactivate the Digital Surroundings too
~/Desktop/Emergency-Voice-Chatbot$ conda deactivate
Fundamental Python Scripts
Let’s first discover the utils.py script.
1. Fundamental Imports
time, tempfile, os, re, BytesIO – Deal with timing, momentary information, atmosphere variables, regex, and in-memory knowledge.
requests – Makes HTTP requests (e.g., calling APIs).
gTTS, elevenlabs, pydub – Convert textual content to speech, speech to textual content and play/manipulate audio.
groq, langchain_* – Use Groq/OpenAI LLMs with LangChain to course of and generate textual content.
streamlit – Construct interactive internet apps.dotenv – Load atmosphere variables (like API keys) from a .env file.
import time
import requests
import tempfile
import re
from io import BytesIO
from gtts import gTTS
from elevenlabs.shopper import ElevenLabs
from elevenlabs import play
from pydub import AudioSegment
from groq import Groq
from langchain_groq import ChatGroq
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import streamlit as st
import os
from dotenv import load_dotenv
load_dotenv() 2. Load your API Keys and initialize your fashions
# Initialize the Groq shopper
shopper = Groq(api_key=os.getenv('GROQ_API_KEY'))
# Initialize the Groq mannequin for LLM responses
llm = ChatOpenAI(
model_name="gpt-4.1-mini",
openai_api_key=os.getenv("COMET_API_KEY"),
openai_api_base="https://api.cometapi.com/v1"
)
# Set the trail to ffmpeg executable
AudioSegment.converter = "/bin/ffmpeg"
3. Changing the Audio file (our voice recording) into .wav format
Right here, we’ll changing our audio in bytes which is finished by AudioSegment and BytesIO and convert it right into a wav format:
def audio_bytes_to_wav(audio_bytes):
attempt:
with tempfile.NamedTemporaryFile(delete=False, suffix=".wav") as temp_wav:
audio = AudioSegment.from_file(BytesIO(audio_bytes))
# Downsample to scale back file dimension if wanted
audio = audio.set_frame_rate(16000).set_channels(1)
audio.export(temp_wav.identify, format="wav")
return temp_wav.identify
besides Exception as e:
st.error(f"Error throughout WAV file conversion: {e}")
return None4. Splitting Audio
We’ll make a operate to separate our audio as per our enter parameter (check_length_ms). We can even make a operate to eliminate any punctuation with the assistance of regex.
def split_audio(file_path, chunk_length_ms):
audio = AudioSegment.from_wav(file_path)
return for i in vary(0, len(audio), chunk_length_ms)]
def remove_punctuation(textual content):
return re.sub(r'[^ws]', '', textual content)5. LLM Response Technology
Now, to do important responder performance the place the LLM will generate an apt response to our queries. Within the immediate template, we’ll present the directions to our LLM on how they need to reply to the queries. We might be implementing Langchain Expression Language to do that job.
def get_llm_response(question, chat_history):
attempt:
template = template = """
You might be an skilled Emergency Response Cellphone Operator skilled to deal with crucial conditions in India.
Your function is to information customers calmly and clearly throughout emergencies involving:
- Medical crises (accidents, coronary heart assaults, and so forth.)
- Hearth incidents
- Police/legislation enforcement help
- Suicide prevention or psychological well being crises
You have to:
1. **Stay calm and assertive**, as if talking on a cellphone name.
2. **Ask for and ensure key particulars** like location, situation of the particular person, variety of folks concerned, and so forth.
3. **Present quick and sensible steps** the person can take earlier than assist arrives.
4. **Share correct, India-based emergency helpline numbers** (e.g., 112, 102, 108, 1091, 1098, 9152987821, and so forth.).
5. **Prioritize person security**, and clearly instruct them what *not* to do as nicely.
6. If the scenario includes **suicidal ideas or psychological misery**, reply with compassion and direct them to acceptable psychological well being helplines and security actions.
If the person's question isn't associated to an emergency, reply with:
"I can solely help with pressing emergency-related points. Please contact a basic assist line for non-emergency questions."
Use an authoritative, supportive tone, brief and direct sentences, and tailor your steerage to **city and rural Indian contexts**.
**Chat Historical past:** {chat_history}
**Consumer:** {user_query}
"""
immediate = ChatPromptTemplate.from_template(template)
chain = immediate | llm | StrOutputParser()
response_gen = chain.stream({
"chat_history": chat_history,
"user_query": question
})
response_text="".be part of(checklist(response_gen))
response_text = remove_punctuation(response_text)
# Take away repeated textual content
response_lines = response_text.break up('n')
unique_lines = checklist(dict.fromkeys(response_lines)) # Eradicating duplicates
cleaned_response="n".be part of(unique_lines)
return cleaned_responseChatbot
besides Exception as e:
st.error(f"Error throughout LLM response technology: {e}")
return "Error"
6. Textual content to Speech
We’ll construct a operate to transform our textual content to speech with the assistance of ElevenLabs TTS Consumer which is able to return us the Audio within the AudioSegment format. We are able to additionally use different TTS fashions like Nari Lab’s Dia or Google’s gTTS too. Eleven Labs supplies us some free credit at begin after which we’ve to pay for extra credit, gTTS on the opposite aspect is completely free to make use of.
def text_to_speech(textual content: str, retries: int = 3, delay: int = 5):
try = 0
whereas try < retries:
attempt:
# Request speech synthesis (streaming generator)
response_stream = tts_client.text_to_speech.convert(
textual content=textual content,
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
# Write streamed bytes to a short lived file
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as f:
for chunk in response_stream:
f.write(chunk)
temp_path = f.identify
# Load and return the audio
audio = AudioSegment.from_mp3(temp_path)
return audio
else:
st.error(f"Failed to attach after {retries} makes an attempt. Please examine your web connection.")
return AudioSegment.silent(length=1000)
besides Exception as e:
st.error(f"Error throughout text-to-speech conversion: {e}")
return AudioSegment.silent(length=1000)
return AudioSegment.silent(length=1000)
7. Create Introductory Message
We can even create an introductory textual content and move it to our TTS mannequin since a respondent would usually introduce themselves and search what help the person may want. Right here we might be returning the trail of the mp3 file.
lang=” en” -> English
tld= ”co.in” -> can produce completely different localized ‘accents’ for a given language. The default is “com”
def create_welcome_message():
welcome_text = (
"Hey, you’ve reached the Emergency Assist Desk. "
"Please let me know if it is a medical, fireplace, police, or psychological well being emergency—"
"I am right here to information you immediately."
)
attempt:
# Request speech synthesis (streaming generator)
response_stream = tts_client.text_to_speech.convert(
textual content=welcome_text,
voice_id="JBFqnCBsd6RMkjVDRZzb",
model_id="eleven_multilingual_v2",
output_format="mp3_44100_128",
)
# Save streamed bytes to temp file
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as f:
for chunk in response_stream:
f.write(chunk)
return f.identify
besides requests.ConnectionError:
st.error("Didn't generate welcome message as a consequence of connection error.")
besides Exception as e:
st.error(f"Error creating welcome message: {e}")
return NoneStreamlit App
Now, let’s bounce into the important.py script the place we might be utilizing Streamlit to visualise our Chatbot.
Import Libraries and Features
Import our libraries and the capabilities we had in-built our utils.py
import tempfile
import re # This may be eliminated if not used
from io import BytesIO
from pydub import AudioSegment
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
import streamlit as st
from audio_recorder_streamlit import audio_recorder
from utils import *Streamlit Setup
Now, we’ll set our Title identify and good “Emergency” visible picture
st.title(":blue[Emergency Help Bot] 🚨🚑🆘")
st.sidebar.picture('./emergency.jpg', use_column_width=True)We’ll set our Session States to maintain monitor of our chats and audio
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
if "chat_histories" not in st.session_state:
st.session_state.chat_histories = []
if "played_audios" not in st.session_state:
st.session_state.played_audios = {}
Invoking our utils capabilities
We’ll create our welcome message introduction from the Respondent aspect. This would be the begin of our dialog.
if len(st.session_state.chat_history) == 0:
welcome_audio_path = create_welcome_message()
st.session_state.chat_history = [
AIMessage(content="Hello, you’ve reached the Emergency Help Desk. Please let me know if it's a medical, fire, police, or mental health emergency—I'm here to guide you right away.", audio_file=welcome_audio_path)
]
st.session_state.played_audios[welcome_audio_path] = False Now, within the sidebar we’ll organising our voice recorder and the speech-to-text, llm_response and the text-to-speech logic which is the principle crux of this mission
with st.sidebar:
audio_bytes = audio_recorder(
energy_threshold=0.01,
pause_threshold=0.8,
textual content="Communicate on clicking the ICON (Max 5 min) n",
recording_color="#e9b61d", # yellow
neutral_color="#2abf37", # inexperienced
icon_name="microphone",
icon_size="2x"
)
if audio_bytes:
temp_audio_path = audio_bytes_to_wav(audio_bytes)
if temp_audio_path:
attempt:
user_input = speech_to_text(audio_bytes)
if user_input:
st.session_state.chat_history.append(HumanMessage(content material=user_input, audio_file=temp_audio_path))
response = get_llm_response(user_input, st.session_state.chat_history)
audio_response = text_to_speech(response) We can even setup a button on the sidebar which is able to enable us to restart our session if wanted be and naturally our introductory voice word from the respondent aspect.
if st.button("Begin New Chat"):
st.session_state.chat_histories.append(st.session_state.chat_history)
welcome_audio_path = create_welcome_message()
st.session_state.chat_history = [
AIMessage(content="Hello, you’ve reached the Emergency Help Desk. Please let me know if it's a medical, fire, police, or mental health emergency—I'm here to guide you right away.", audio_file=welcome_audio_path)
]And in the principle web page of our App, we might be visualizing our Chat Historical past within the type of Click on to Play Audio file
for msg in st.session_state.chat_history:
if isinstance(msg, AIMessage):
with st.chat_message("AI"):
st.audio(msg.audio_file, format="audio/mp3")
else: # HumanMessage
with st.chat_message("person"):
st.audio(msg.audio_file, format="audio/wav")Now, we’re achieved with the entire Python scripts wanted to run our app. We’ll run the Streamlit App utilizing the next Command:
streamlit run app.py So, that is what our Undertaking Workflow appears to be like like:
[User speaks] → audio_recorder → audio_bytes_to_wav → speech_to_text → get_llm_response → text_to_speech → st.audio
For the complete code, go to this GitHub repository.
Last Output
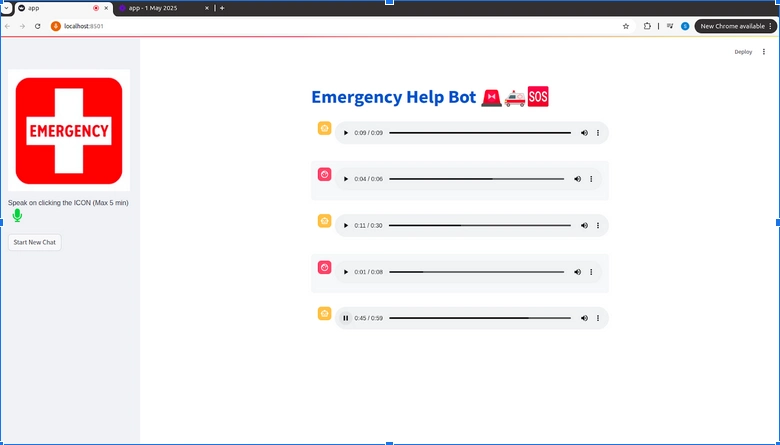
The Streamlit App appears to be like fairly clear and is functioning appropriately!
Let’s see a few of its responses:-
- Consumer: Hello, somebody is having a coronary heart assault proper now, what ought to I do?
We then had a dialog on the placement and state of the particular person after which the Chatbot offered this
- Consumer: Hey, there was an enormous fireplace breakout in Delhi. Please ship assist fast
Respondent enquires concerning the scenario and the place is my present location after which proceeds to supply preventive measures accordingly
- Consumer: Hey there, there’s a particular person standing alone throughout the sting of the bridge, how ought to i proceed?
The Respondent enquires concerning the location the place I’m and the psychological state of the particular person I’ve talked about
Total, our chatbot is ready to answer our queries in accordance to the scenario and asks the related questions to supply preventive measures.
Learn Extra: Easy methods to construct a chatbot in Python?
What Enhancements might be made?
- Multilingual Assist: Can combine LLMs with robust multilingual capabilities which may enable the chatbot to work together seamlessly with customers from completely different areas and dialects.
- Actual-Time Transcription and Translation: Including speech-to-text and real-time translation can assist bridge communication gaps.
- Location-Primarily based Providers: By integrating GPS or different real-time location-based APIs, the system can detect a person’s location and information the closest emergency services.
- Speech-to-Speech Interplay: We are able to additionally use speech-to-speech fashions which may make conversations really feel extra pure since they’re constructed for such functionalities.
- Positive-tuning the LLM: Customized fine-tuning of the LLM primarily based on emergency-specific knowledge can enhance its understanding and supply extra correct responses.
To be taught extra about AI-powered voice brokers, observe these assets:
Conclusion
On this article, we efficiently constructed a voice-based emergency response chatbot utilizing a mix of AI fashions and a few related instruments. This chatbot replicates the function of a skilled emergency operator which is able to dealing with high-stress conditions from medical crises, and fireplace incidents to psychological well being assist utilizing a peaceful, assertive that may alter the habits of our LLM to go well with the varied real-world emergencies, making the expertise extra reasonable for each city and rural situation.
GenAI Intern @ Analytics Vidhya | Last 12 months @ VIT Chennai
Captivated with AI and machine studying, I am desperate to dive into roles as an AI/ML Engineer or Information Scientist the place I could make an actual affect. With a knack for fast studying and a love for teamwork, I am excited to convey modern options and cutting-edge developments to the desk. My curiosity drives me to discover AI throughout varied fields and take the initiative to delve into knowledge engineering, making certain I keep forward and ship impactful initiatives.
Login to proceed studying and revel in expert-curated content material.