Generative AI has reshaped how folks create, think about and work together with digital content material.
As AI fashions proceed to develop in functionality and complexity, they require extra VRAM, or video random entry reminiscence. The bottom Secure Diffusion 3.5 Giant mannequin, for instance, makes use of over 18GB of VRAM — limiting the variety of methods that may run it properly.
By making use of quantization to the mannequin, noncritical layers might be eliminated or run with decrease precision. NVIDIA GeForce RTX 40 Collection and the Ada Lovelace era of NVIDIA RTX PRO GPUs assist FP8 quantization to assist run these quantized fashions, and the latest-generation NVIDIA Blackwell GPUs additionally add assist for FP4.
NVIDIA collaborated with Stability AI to quantize its newest mannequin, Secure Diffusion (SD) 3.5 Giant, to FP8 — decreasing VRAM consumption by 40%. Additional optimizations to SD3.5 Giant and Medium with the NVIDIA TensorRT software program improvement equipment (SDK) double efficiency.
As well as, TensorRT has been reimagined for RTX AI PCs, combining its industry-leading efficiency with just-in-time (JIT), on-device engine constructing and an 8x smaller package deal dimension for seamless AI deployment to greater than 100 million RTX AI PCs. TensorRT for RTX is now accessible as a standalone SDK for builders.
RTX-Accelerated AI
NVIDIA and Stability AI are boosting the efficiency and decreasing the VRAM necessities of Secure Diffusion 3.5, one of many world’s hottest AI picture fashions. With NVIDIA TensorRT acceleration and quantization, customers can now generate and edit photographs quicker and extra effectively on NVIDIA RTX GPUs.

To deal with the VRAM limitations of SD3.5 Giant, the mannequin was quantized with TensorRT to FP8, decreasing the VRAM requirement by 40% to 11GB. This implies 5 GeForce RTX 50 Collection GPUs can run the mannequin from reminiscence as an alternative of only one.
SD3.5 Giant and Medium fashions have been additionally optimized with TensorRT, an AI backend for taking full benefit of Tensor Cores. TensorRT optimizes a mannequin’s weights and graph — the directions on the way to run a mannequin — particularly for RTX GPUs.
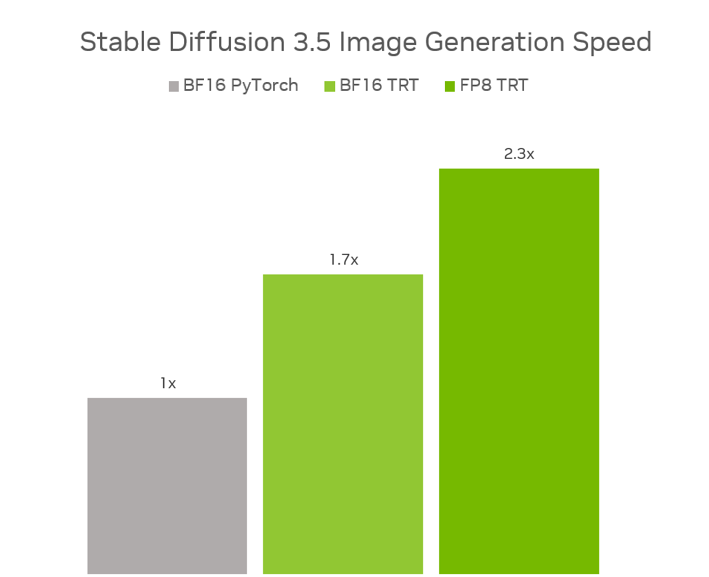
Mixed, FP8 TensorRT delivers a 2.3x efficiency increase on SD3.5 Giant in contrast with operating the unique fashions in BF16 PyTorch, whereas utilizing 40% much less reminiscence. And in SD3.5 Medium, BF16 TensorRT gives a 1.7x efficiency enhance in contrast with BF16 PyTorch.
The optimized fashions are actually accessible on Stability AI’s Hugging Face web page.
NVIDIA and Stability AI are additionally collaborating to launch SD3.5 as an NVIDIA NIM microservice, making it simpler for creators and builders to entry and deploy the mannequin for a variety of functions. The NIM microservice is predicted to be launched in July.
TensorRT for RTX SDK Launched
Introduced at Microsoft Construct — and already accessible as a part of the brand new Home windows ML framework in preview — TensorRT for RTX is now accessible as a standalone SDK for builders.
Beforehand, builders wanted to pre-generate and package deal TensorRT engines for every class of GPU — a course of that will yield GPU-specific optimizations however required important time.
With the brand new model of TensorRT, builders can create a generic TensorRT engine that’s optimized on machine in seconds. This JIT compilation strategy might be carried out within the background throughout set up or after they first use the characteristic.
The simple-to-integrate SDK is now 8x smaller and might be invoked via Home windows ML — Microsoft’s new AI inference backend in Home windows. Builders can obtain the brand new standalone SDK from the NVIDIA Developer web page or take a look at it within the Home windows ML preview.
For extra particulars, learn this NVIDIA technical weblog and this Microsoft Construct recap.
Be a part of NVIDIA at GTC Paris
At NVIDIA GTC Paris at VivaTech — Europe’s largest startup and tech occasion — NVIDIA founder and CEO Jensen Huang yesterday delivered a keynote deal with on the most recent breakthroughs in cloud AI infrastructure, agentic AI and bodily AI. Watch a replay.
GTC Paris runs via Thursday, June 12, with hands-on demos and periods led by {industry} leaders. Whether or not attending in particular person or becoming a member of on-line, there’s nonetheless loads to discover on the occasion.
Every week, the RTX AI Storage weblog collection options community-driven AI improvements and content material for these trying to study extra about NVIDIA NIM microservices and AI Blueprints, in addition to constructing AI brokers, inventive workflows, digital people, productiveness apps and extra on AI PCs and workstations.
Plug in to NVIDIA AI PC on Fb, Instagram, TikTok and X — and keep knowledgeable by subscribing to the RTX AI PC e-newsletter.
Comply with NVIDIA Workstation on LinkedIn and X.
See discover relating to software program product data.