Guide information entry from invoices is a sluggish, error-prone job that companies have battled for many years. Lately, Uber Engineering revealed how they tackled this problem with their “TextSense” platform, a complicated system for GenAI bill processing. This technique showcases the ability of clever doc processing, combining Optical Character Recognition (OCR) with Giant Language Fashions (LLMs) for extremely correct, automated information extraction. This superior strategy may appear out of attain for smaller tasks. Nonetheless, the core rules are actually accessible to everybody. This information will present you replicate the basic workflow of Uber’s system. We’ll use easy, highly effective instruments to create a system that automates bill information extraction.
Understanding Uber’s “TextSense” System
Earlier than we construct our model, it’s useful to grasp what impressed it. Uber’s objective was to automate the processing of thousands and thousands of paperwork, from invoices to receipts. Their “TextSense” platform, detailed of their engineering weblog, is a sturdy, multi-stage pipeline designed for this function.
The determine reveals the total doc processing pipeline. For processing any doc, pre-processing is often widespread earlier than calling an LLM.
At its core, the system works in three primary levels:
- Digitization (by way of OCR): First, the system takes a doc, like a PDF or a picture of an bill. It makes use of a complicated OCR engine to “learn” the doc and convert all of the visible textual content into machine-readable textual content. This uncooked textual content is the muse for the subsequent step.
- Clever Extraction (by way of LLM): The uncooked textual content from the OCR course of is commonly messy and unstructured. That is the place the GenAI magic occurs. Uber feeds this textual content to a big language mannequin. The LLM acts like an knowledgeable who understands the context of an bill. It may well establish and extract particular items of data, such because the “Bill Quantity,” “Whole Quantity,” and “Provider Identify,” and arrange them right into a structured format, like JSON.
- Verification (Human-in-the-Loop): No AI is ideal. To make sure 100% accuracy, Uber applied a human-in-the-loop AI system. This verification step presents the unique doc alongside the AI-extracted information to a human operator. The operator can rapidly affirm that the information is appropriate or make minor changes if wanted. This suggestions loop additionally helps enhance the mannequin over time.
This mixture of OCR with AI and human oversight makes their system each environment friendly and dependable. The next determine explains the workflow of TextSense in an in depth method, as defined within the above factors.
Our Sport Plan: Replicating the Core Workflow
Our objective is to not rebuild Uber’s whole production-grade platform. As an alternative, we are going to replicate its core intelligence in a simplified, accessible means. We’ll construct our GenAI bill processing POC in a single Google Colab pocket book.
Our plan follows the identical logical steps:
- Ingest Doc: We’ll create a easy method to add a PDF bill on to our pocket book.
- Carry out OCR: We’ll use Tesseract, a strong open-source OCR engine, to extract all of the textual content from the uploaded bill.
- Extract Entities with AI: We’ll use the Google Gemini API to carry out the automated information extraction. We’ll craft a particular immediate to instruct the mannequin to tug out the important thing fields we want.
- Create a Verification UI: We’ll construct a easy interactive interface utilizing ipywidgets to function our human-in-the-loop AI system, permitting for fast validation of the extracted information.
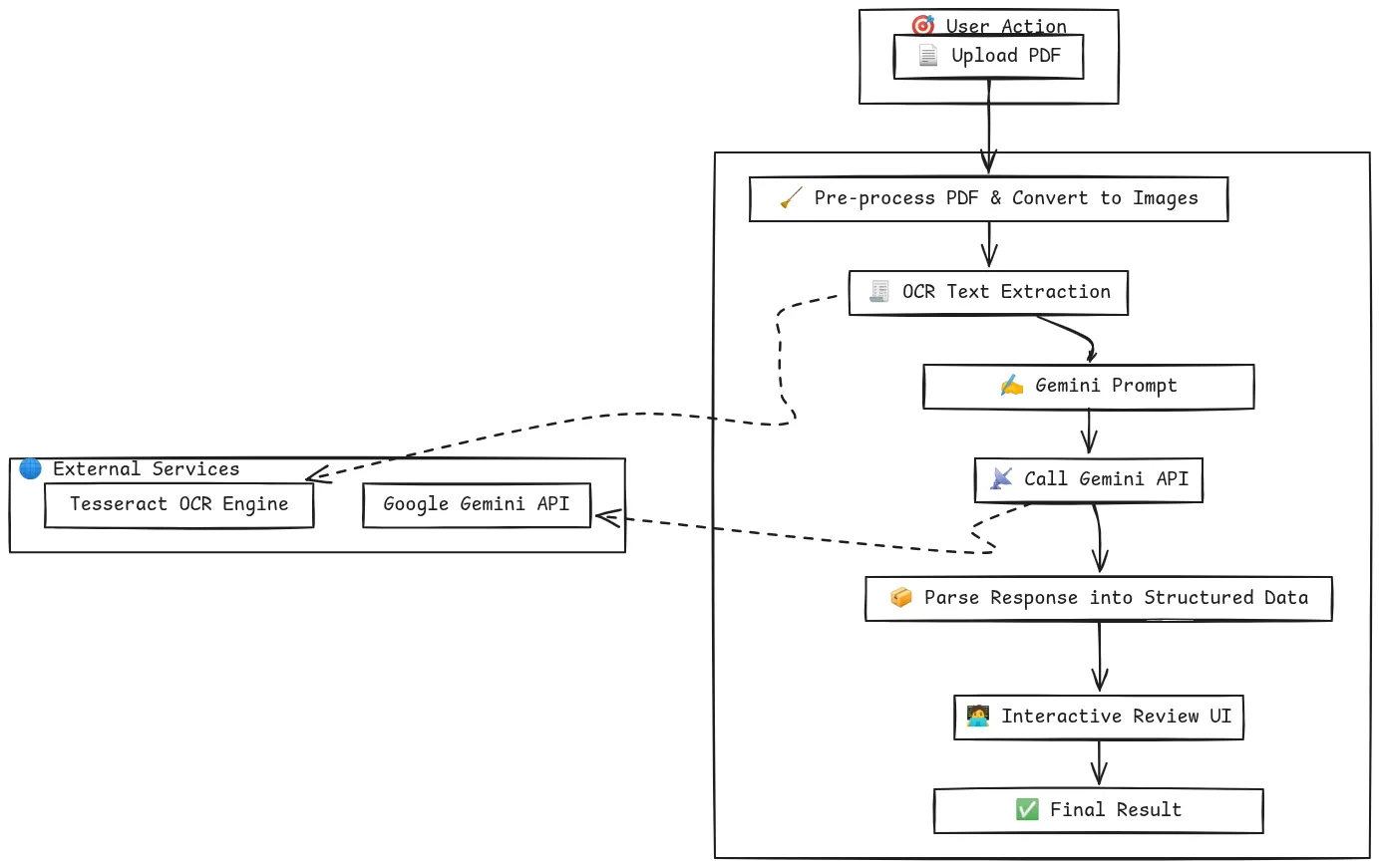
This strategy provides us a strong and cheap method to obtain clever doc processing with no need complicated infrastructure.
Fingers-On Implementation: Constructing the POC Step-by-Step
Let’s start constructing our system. You possibly can observe these steps in a brand new Google Colab pocket book.
Step 1: Setting Up the Atmosphere
First, we have to set up the required Python libraries. This command installs packages for dealing with PDFs (PyMuPDF), operating OCR (pytesseract), interacting with the Gemini API, and constructing the UI (ipywidgets). It additionally installs the Tesseract OCR engine itself.
!pip set up -q -U google-generativeai PyMuPDF pytesseract pandas ipywidgets
!apt-get -qq set up tesseract-ocrStep 2: Configuring the Google Gemini API
Subsequent, you should configure your Gemini API key. To maintain your key secure, we’ll use Colab’s built-in secret supervisor.
- Get your API key from Google AI Studio.
- In your Colab pocket book, click on the important thing icon on the left sidebar.
- Create a brand new secret named GEMINI_API_KEY and paste your key as the worth.
The next code will securely entry your key and configure the API.
import google.generativeai as genai
from google.colab import userdata
import fitz # PyMuPDF
import pytesseract
from PIL import Picture
import pandas as pd
import ipywidgets as widgets
from ipywidgets import Structure
from IPython.show import show, clear_output
import json
import io
# Configure the Gemini API
attempt:
api_key = userdata.get(“GEMINI_API_KEY”)
genai.configure(api_key=api_key)
print("Gemini API configured efficiently.")
besides userdata.SecretNotFoundError:
print("ERROR: Secret 'GEMINI_API_KEY' not discovered. Please observe the directions to set it up.")Step 3: Importing and Pre-processing the PDF
This code uploads a PDF file that’s an bill PDF. Once you add a PDF, it converts every web page right into a high-resolution picture, which is the best format for OCR.
import fitz # PyMuPDF
from PIL import Picture
import io
import os
invoice_images = []
uploaded_file_name = "/content material/sample-invoice.pdf" # Exchange with the precise path to your PDF file
# Make sure the file exists (optionally available however really useful)
if not os.path.exists(uploaded_file_name):
print(f"ERROR: File not discovered at '{uploaded_file_name}'. Please replace the file path.")
else:
print(f"Processing '{uploaded_file_name}'...")
# Convert PDF to pictures
doc = fitz.open(uploaded_file_name)
for page_num in vary(len(doc)):
web page = doc.load_page(page_num)
pix = web page.get_pixmap(dpi=300) # Larger DPI for higher OCR
img = Picture.open(io.BytesIO(pix.tobytes()))
invoice_images.append(img)
doc.shut()
print(f"Efficiently transformed {len(invoice_images)} web page(s) to pictures.")
# Show the primary web page as a preview
if invoice_images:
print("n--- Bill Preview (First Web page) ---")
show(invoice_images[0].resize((600, 800)))Output:

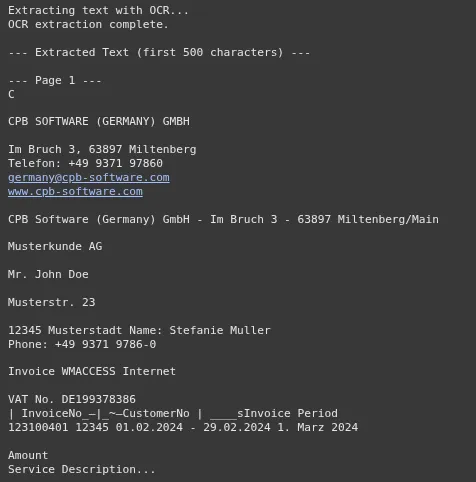
Now, we run the OCR course of on the photographs we simply created. The textual content from all pages is mixed right into a single string. That is the context we are going to ship to the Gemini mannequin. This step is an important a part of the OCR with AI workflow.
full_invoice_text = ""
if not invoice_images:
print("Please add a PDF bill within the step above first.")
else:
print("Extracting textual content with OCR...")
for i, img in enumerate(invoice_images):
textual content = pytesseract.image_to_string(img)
full_invoice_text += f"n--- Web page {i+1} ---n{textual content}"
print("OCR extraction full.")
print("n--- Extracted Textual content (first 500 characters) ---")
print(full_invoice_text[:500] + "...")Output:
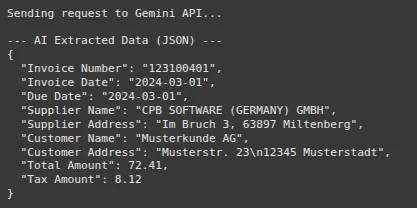
That is the place the GenAI bill processing occurs. We create an in depth immediate that tells the Gemini mannequin its position. We instruct it to extract particular fields and return the end in a clear JSON format. Asking for JSON is a strong method that makes the mannequin’s output structured and straightforward to work with.
extracted_data = {}
if not full_invoice_text.strip():
print("Can't proceed. The extracted textual content is empty. Please test the PDF high quality.")
else:
# Instantiate the Gemini Professional mannequin
mannequin = genai.GenerativeModel('gemini-2.5-pro')
# Outline the fields you wish to extract
fields_to_extract = "Bill Quantity, Bill Date, Due Date, Provider Identify, Provider Handle, Buyer Identify, Buyer Handle, Whole Quantity, Tax Quantity"
# Create the detailed immediate
immediate = f"""
You might be an knowledgeable in bill information extraction.
Your job is to investigate the supplied OCR textual content from an bill and extract the next fields: {fields_to_extract}.
Observe these guidelines strictly:
1. Return the output as a single, clear JSON object.
2. The keys of the JSON object have to be precisely the sphere names supplied.
3. If a subject can't be discovered within the textual content, its worth within the JSON needs to be `null`.
4. Don't embody any explanatory textual content, feedback, or markdown formatting (like ```json) in your response. Solely the JSON object is allowed.
Right here is the bill textual content:
---
{full_invoice_text}
---
"""
print("Sending request to Gemini API...")
attempt:
# Name the API
response = mannequin.generate_content(immediate)
# Robustly parse the JSON response
response_text = response.textual content.strip()
# Clear potential markdown formatting
if response_text.startswith('```json'):
response_text = response_text[7:-3].strip()
extracted_data = json.hundreds(response_text)
print("n--- AI Extracted Knowledge (JSON) ---")
print(json.dumps(extracted_data, indent=2))
besides json.JSONDecodeError:
print("n--- ERROR ---")
print("Didn't decode the mannequin's response into JSON.")
print("Mannequin's Uncooked Response:", response.textual content)
besides Exception as e:
print(f"nAn surprising error occurred: {e}")
print("Mannequin's Uncooked Response (if out there):", getattr(response, 'textual content', 'N/A'))Output:
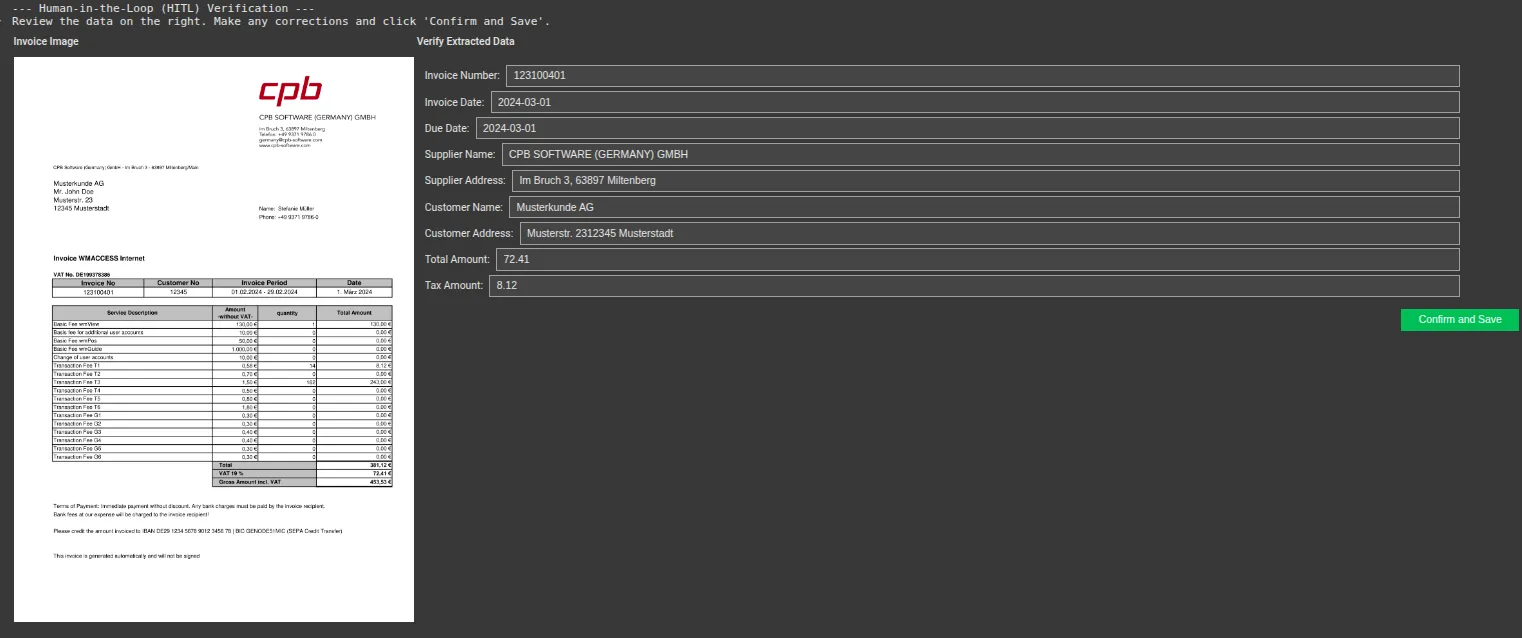
Step 6: Constructing the Human-in-the-Loop (HITL) UI
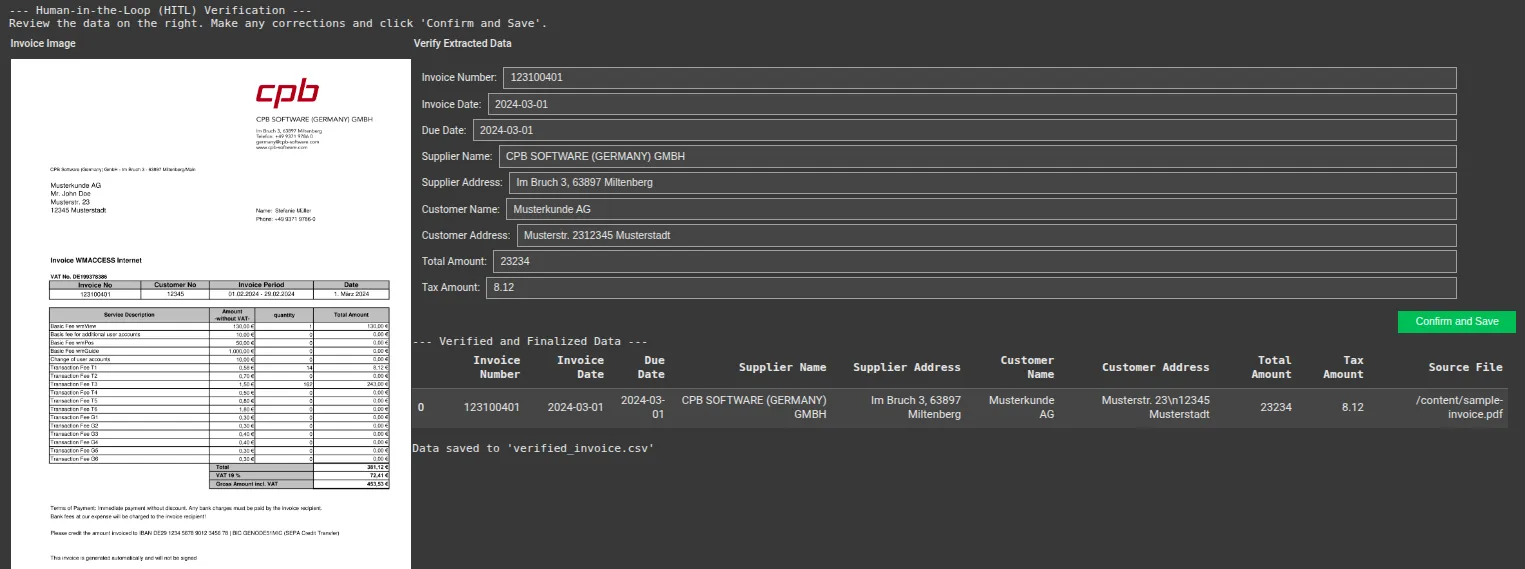
Lastly, we constructed the verification interface. This code shows the bill picture on the left and creates an editable type on the suitable, pre-filled with the information from Gemini. The consumer can rapidly assessment the knowledge, make any obligatory edits, and make sure.
# UI Widgets
text_widgets = {}
if not extracted_data:
print("No information was extracted by the AI. Can't construct verification UI.")
else:
form_items = []
# Create a textual content widget for every extracted subject
for key, worth in extracted_data.gadgets():
text_widgets[key] = widgets.Textual content(
worth=str(worth) if worth is just not None else "",
description=key.change('_', ' ').title() + ':',
fashion={'description_width': 'preliminary'},
structure=Structure(width="95%")
)
form_items.append(text_widgets[key])
# The shape container
type = widgets.VBox(form_items, structure=Structure(padding='10px'))
# Picture container
if invoice_images:
img_byte_arr = io.BytesIO()
invoice_images[0].save(img_byte_arr, format="PNG")
image_widget = widgets.Picture(
worth=img_byte_arr.getvalue(),
format="png",
width=500
)
image_box = widgets.HBox([image_widget], structure=Structure(justify_content="middle"))
else:
image_box = widgets.HTML("No picture to show.")
# Affirmation button
confirm_button = widgets.Button(description="Verify and Save", button_style="success")
output_area = widgets.Output()
def on_confirm_button_clicked(b):
with output_area:
clear_output()
final_data = {key: widget.worth for key, widget in text_widgets.gadgets()}
# Create a pandas DataFrame
df = pd.DataFrame([final_data])
df['Source File'] = uploaded_file_name
print("--- Verified and Finalized Knowledge ---")
show(df)
# Now you can save this DataFrame to CSV, and many others.
df.to_csv('verified_invoice.csv', index=False)
print("nData saved to 'verified_invoice.csv'")
confirm_button.on_click(on_confirm_button_clicked)
# Remaining UI Structure
ui = widgets.HBox([
widgets.VBox([widgets.HTML("<b>Invoice Image</b>"), image_box]),
widgets.VBox([
widgets.HTML("<b>Verify Extracted Data</b>"),
form,
widgets.HBox([confirm_button], structure=Structure(justify_content="flex-end")),
output_area
], structure=Structure(flex='1'))
])
print("--- Human-in-the-Loop (HITL) Verification ---")
print("Assessment the information on the suitable. Make any corrections and click on 'Verify and Save'.")
show(ui)Output:
Modify some values after which save.
Output:
You possibly can entry the total code right here: GitHub, Colab
Conclusion
This POC efficiently demonstrates that the core logic behind a complicated system like Uber’s “TextSense” is replicable. By combining open-source OCR with a strong LLM like Google’s Gemini, you possibly can construct an efficient system for GenAI bill processing. This strategy to clever doc processing dramatically reduces handbook effort and improves accuracy. The addition of a easy human-in-the-loop AI interface ensures that the ultimate information is reliable.
Be happy to develop on this basis by including extra fields, bettering validation, and integrating it into bigger workflows.
Incessantly Requested Questions
A. The accuracy could be very excessive, particularly with clear invoices. The Gemini mannequin is great at understanding context, however high quality can lower if the OCR textual content is poor resulting from a low-quality scan.
A. Sure. Not like template-based methods, the LLM understands language and context. This enables it to seek out fields like “Bill Quantity” or “Whole” no matter their place on the web page.
A. The associated fee is minimal. Tesseract and the opposite libraries are free. You solely pay in your utilization of the Google Gemini API, which could be very reasonably priced for this sort of job.
A. Completely. Merely add the brand new subject names to the fields_to_extract string in Step 5, and the Gemini mannequin will try to seek out them for you.
A. Guarantee your supply PDFs are high-resolution. Within the code, we set dpi=300 when changing the PDF to a picture, which is an effective commonplace for OCR. Larger DPI can typically yield higher outcomes for blurry paperwork.
Harsh Mishra is an AI/ML Engineer who spends extra time speaking to Giant Language Fashions than precise people. Keen about GenAI, NLP, and making machines smarter (in order that they don’t change him simply but). When not optimizing fashions, he’s most likely optimizing his espresso consumption. 🚀☕
Login to proceed studying and revel in expert-curated content material.