Have you ever ever used Zepto for ordering groceries on-line? You have to have seen that when you even write a flawed phrase or misspell a reputation, Zepto nonetheless understands and exhibits you the right outcomes that you just had been in search of. Customers typing “kele chips” as an alternative of “banana chips” battle to seek out what they need. Misspellings and vernacular queries result in poor consumer expertise and diminished conversions. Zepto’s information science crew constructed a sturdy system to sort out this downside utilizing LLM and RAG to repair multilingual misspellings. On this information, we will likely be replicating this end-to-end function from fuzzy question to corrected output. This information explains how tech issues in search high quality and multilingual question decision.
Understanding Zepto’s System
Technical Movement
Let’s perceive the technical movement that Zepto is utilizing for its multilingual question decision. This movement entails a number of parts that we are going to stroll via in a while.
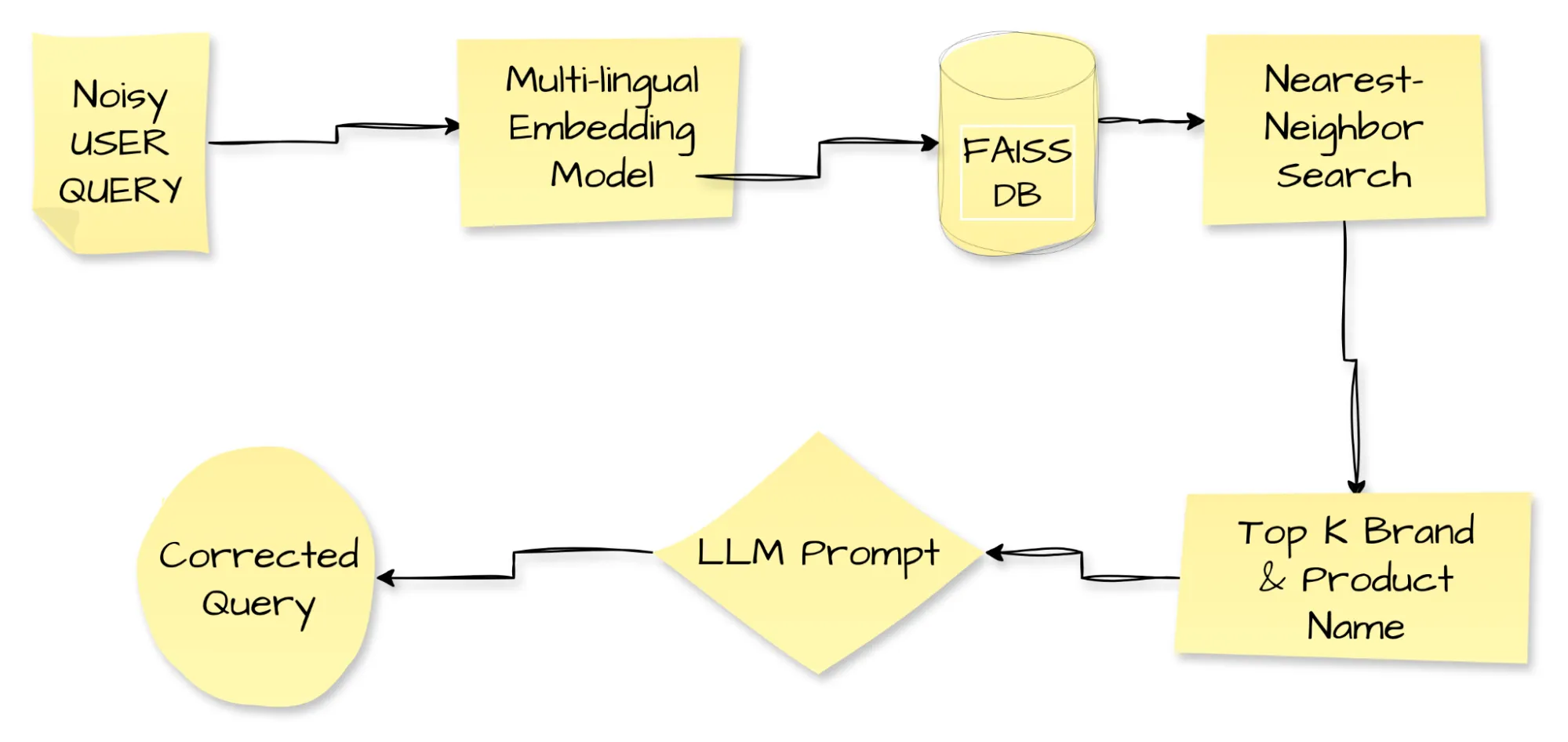
The diagram traces a loud consumer question via its full correction journey. The misspelled or vernacular textual content enters the pipeline; a multilingual embedding mannequin converts it right into a dense vector. The system feeds this vector into FAISS, Fb’s similarity-search engine, which returns the highest Ok model and product names that sit closest in embedding area. Subsequent, the pipeline forwards each the noisy question and the retrieved names to an LLM immediate, and the LLM outputs a clear, corrected question. Zepto deploys this query-resolution loop to sharpen consumer expertise and raise conversions. Dealing with incorrect spellings, code-mixed phrases, and regional languages, Zepto logged a 7.5 % bounce in conversion charges for affected queries, a transparent demonstration of expertise’s energy to raise on a regular basis interactions.
Core Parts
Let’s now give attention to the core ideas that we’re utilizing on this system.
1. Misspelled Queries & Vernacular Queries
Customers typically kind vernacular phrases utilizing a mixture of English and regional phrases in a single question. For instance, “kele chips” (“banana chips”), “balekayi chips” (Kannada), and so on. Phonetic typing, like “kothimbir” (phonetically typed Marathi/Hindi phrase for coriander) or “paal” for milk in Tamil, makes the standard search battle right here. The which means will get misplaced with out normalization or transliteration help.
2. RAG (Retrieval-Augmented Era
RAG is a pipeline that mixes semantic retrieval (vector embeddings and metadata lookup) with LLM technology capabilities. Zepto utilised RAG performance to retrieve the highest ok related product names and types when receiving a loud, misspelled, and vernacular question. Then, these most comparable retrieved product or model names are fed to LLMs together with the noisy question for correction.
Advantages of utilizing RAG in Zepto’s use case:
- Grounds LLM by stopping hallucination by offering context.
- Improves accuracy & ensures related brand-term corrections.
- Reduces immediate measurement and inference value by narrowing context.
3. Vector Database
A Vector database is a specialised kind of database designed to retailer, index phrase or sentence embeddings, that are numerical representations of knowledge factors. These vector databases are used to retrieve high-dimensional vectors utilizing a similarity search when given a question. FAISS is an open-source library particularly designed for environment friendly similarity search and clustering of dense vectors in an environment friendly method. FAISS is used for shortly trying to find comparable embeddings of multimedia paperwork. In Zepto’s system, they’re utilizing FAISS to retailer the embeddings of their model names, tags, and product names.
4. Stepwise Prompting & JSON Output
Zepto’s movement mentions a modular immediate breakdown whose important motive is to interrupt down the complicated process into small stepwise duties after which carry out it effectively with none errors, enhancing accuracy. It entails detecting if the question is misspelled or vernacular, correcting the phrases, translating to English canonical phrases, and outputting as a JSON construction.
JSON schema ensures reliability and readability, for instance:
{
"original_query": "...",
"corrected_query": "...",
"translation": "..."
}Their system immediate entails few-shot examples, which include a mixture of English and vernacular corrections to information LLM habits.
5. In-Home LLM Internet hosting
Zepto makes use of Meta’s Llama3-8B, hosted on Databricks for value management and efficiency. They use Instruct fine-tuning, which is a light-weight tuning utilizing stepwise prompts and role-playing directions. It ensures that LLM focuses solely on prompt-level habits, avoiding expensive mannequin retraining
6. Implicit Suggestions by way of Consumer Reformulations
Consumer suggestions is important when your function remains to be new. Every fast correction and higher consequence Zepto customers see counts as a sound repair. Collect these indicators so as to add contemporary few-shot examples to the immediate, drop new synonyms into the retrieval DB, and squash bugs. Zepto’s A/B check exhibits a 7.5 % raise in conversion.
Replicating the Question Decision System
Now, we are going to attempt to replicate Zepto’s multilingual question decision system by defining our system. Let’s take a look on the movement chart of the system under, which we’re going to use.
Our implementation follows the identical technique outlined by Zepto:
- Semantic Retrieval: We first take the consumer’s uncooked question and discover a listing of top-k probably related merchandise from our total catalog. That is achieved by evaluating the question’s vector embedding towards the embeddings of our merchandise saved in a vector database. This step offers the required context.
- LLM-Powered Correction and Choice: The retrieved merchandise (the context) and the unique question are then handed to a Massive Language Mannequin (LLM). The LLM’s process isn’t just to appropriate spelling, however to investigate the context and choose the almost definitely product the consumer supposed to seek out. It then returns a clear, corrected question and the reasoning behind its choice in a structured format.
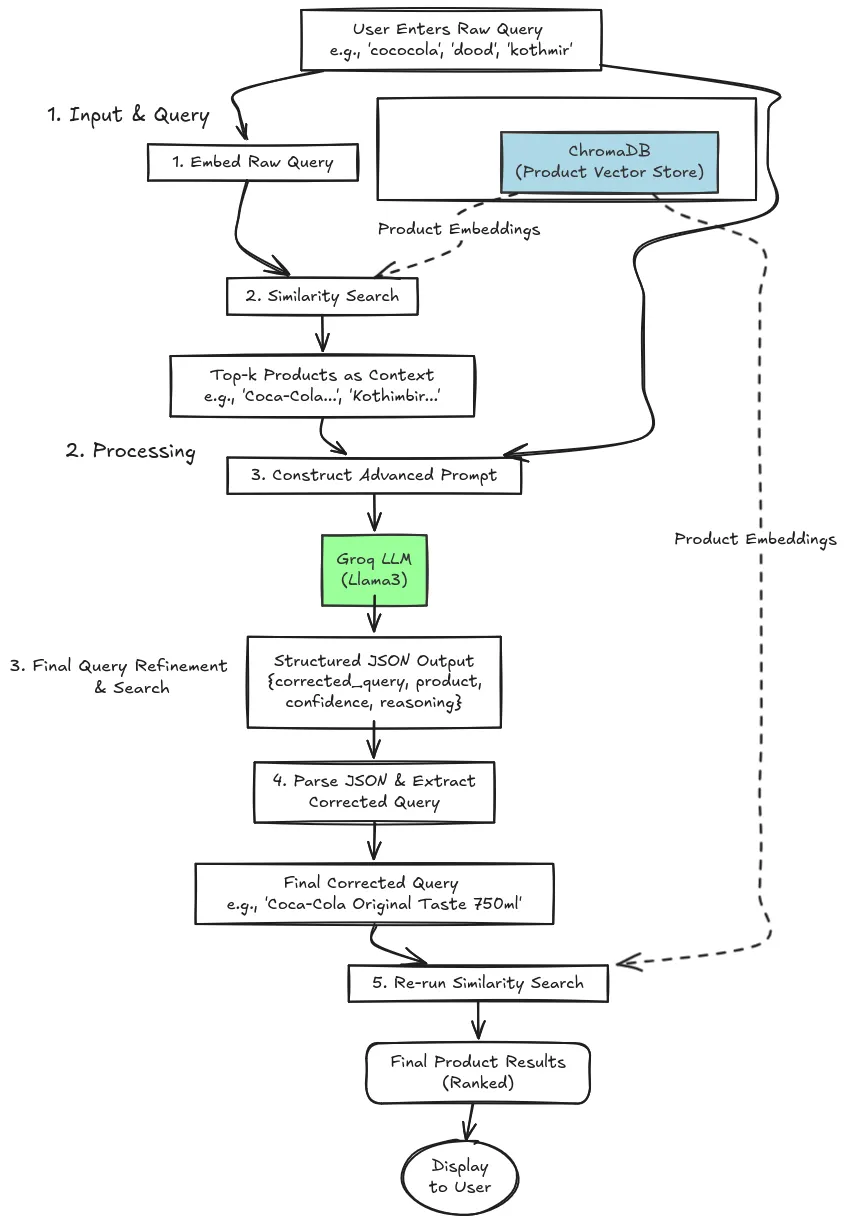
Process
The method may be simplified within the following 3 steps:
- Enter and Question
The consumer enters the uncooked question, which can include some noise or be in a unique language. Our system instantly embeds the uncooked question into multilingual embeddings. A similarity search is carried out on the Chroma DB vector database that has some pre-defined embeddings. It returns the highest ok most related product embeddings.
- Processing
After retrieving the top-k product embeddings, feed them together with the noisy consumer question into Llama3 via a sophisticated system immediate. The mannequin returns a crisp JSON holding the cleaned question, product identify, confidence rating, and its reasoning, letting you see precisely why it selected that model. This ensures a clear correction of the question through which now we have entry to the LLM’s reasoning why it chosen this product and model’s identify because the corrected question.
- Closing Question Refinement and Search
This stage entails the parsing of JSON output from the LLM, by extracting the corrected question, now we have entry to probably the most related product or model identify based mostly on the uncooked question entered by the consumer. The final stage entails rerunning the similarity search on the Vector DB to seek out the small print of the searched product. On this method, we can implement the multilingual question decision system.
Palms-on Implementation
We understood the working of our question decision system, now let’s implement the system utilizing code hands-on. We will likely be doing every little thing step-by-step, from putting in the dependencies to the final similarity search.
Step 1: Putting in the Dependencies
First, we set up the required Python libraries. We’ll use langchain for orchestrating the parts, langchain-groq for the quick LLM inference, fastembed for environment friendly embeddings, langchain-chroma for the vector database, and pandas for information dealing with.
!pip set up -q pandas langchain langchain-core langchain-groq langchain-chroma fastembed langchain-communityStep 2: Create an Expanded and Complicated Dummy Dataset
To completely check the system, we’d like a dataset that displays real-world challenges. This CSV contains:
- A greater variety of merchandise (20+).
- Widespread model names (e.g., Coca-Cola, Maggi).
- Multilingual and vernacular phrases (dhaniya, kanda, nimbu).
- Probably ambiguous objects (cheese unfold, cheese slices).
import pandas as pd
from io import StringIO
csv_data = """product_id,product_name,class,tags
1,Aashirvaad Choose Atta 5kg,Staples,"atta, flour, gehu, aata, wheat"
2,Amul Gold Milk 1L,Dairy,"milk, doodh, paal, full cream milk"
3,Tata Salt 1kg,Staples,"salt, namak, uppu"
4,Kellogg's Corn Flakes 475g,Breakfast,"cornflakes, breakfast cereal, makkai"
5,Parle-G Gold Biscuit 1kg,Snacks,"biscuit, cookies, biscuits"
6,Cadbury Dairy Milk Silk,Goodies,"chocolate, choco, silk, dairy milk"
7,Haldiram's Traditional Banana Chips,Snacks,"kele chips, banana wafers, chips"
8,MDH Deggi Mirch Masala,Spices,"mirchi, masala, spice, purple chili powder"
9,Recent Coriander Bunch (Dhaniya),Greens,"coriander, dhaniya, kothimbir, cilantro"
10,Recent Mint Leaves Bunch (Pudina),Greens,"mint, pudhina, pudina patta"
11,Taj Mahal Purple Label Tea 500g,Drinks,"tea, chai, chaha, purple label"
12,Nescafe Traditional Espresso 100g,Drinks,"espresso, koffee, nescafe"
13,Onion 1kg (Kanda),Greens,"onion, kanda, pyaz"
14,Tomato 1kg,Greens,"tomato, tamatar"
15,Coca-Cola Unique Style 750ml,Drinks,"coke, coca-cola, gentle drink, chilly drink"
16,Maggi 2-Minute Noodles Masala,Snacks,"maggi, noodles, immediate meals"
17,Amul Cheese Slices 100g,Dairy,"cheese, cheese slice, paneer slice"
18,Britannia Cheese Unfold 180g,Dairy,"cheese, cheese unfold, creamy cheese"
19,Recent Lemon 4pcs (Nimbu),Greens,"lemon, nimbu, lime"
20,Saffola Gold Edible Oil 1L,Staples,"oil, tel, cooking oil, saffola"
21,Basmati Rice 1kg,Staples,"rice, chawal, basmati"
22,Kurkure Masala Munch,Snacks,"kurkure, snacks, chips"
"""
df = pd.read_csv(StringIO(csv_data))
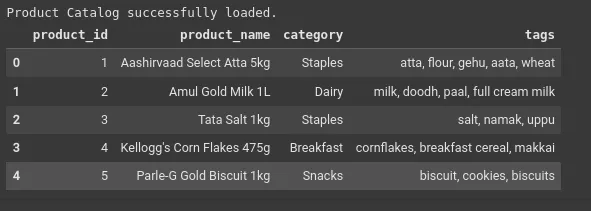
print("Product Catalog efficiently loaded.")
df.head()Output:
Step 3: Initialize a Vector Database
We’ll convert our product information into numerical representations (embeddings) that seize semantic which means. We use FastEmbed for this, because it’s quick and runs domestically. Retailer these embeddings in ChromaDB, a light-weight vector retailer.
Embedding Technique: For every product, we create a single textual content doc that mixes its identify, class, and tags. This creates a wealthy, descriptive embedding that improves the possibilities of a profitable semantic match.
Embedding Mannequin: We’re utilizing the BAAI/bge-small-en-v1.5 mannequin right here. The “small” model of the mannequin is resource-efficient, quick, and an acceptable embedding mannequin for multilingual duties. BAAI/bge-small-en-v1.5 is a powerful English textual content embedding mannequin and may be helpful in sure contexts. It provides aggressive efficiency in duties involving semantic similarity and textual content retrieval.
import os
import json
from langchain.schema import Doc
from langchain.embeddings import FastEmbedEmbeddings
from langchain_chroma import Chroma
# Create LangChain Paperwork
paperwork = [
Document(
page_content=f"{row['product_name']}. Class: {row['category']}. Tags: {row['tags']}",
metadata={
"product_id": row['product_id'],
"product_name": row['product_name'],
"class": row['category']
}
) for _, row in df.iterrows()
]
# Initialize embedding mannequin and vector retailer
embedding_model = FastEmbedEmbeddings(model_name="BAAI/bge-small-en-v1.5")
vectorstore = Chroma.from_documents(paperwork, embedding_model)
# The retriever will likely be used to fetch the top-k most comparable paperwork
retriever = vectorstore.as_retriever(search_kwargs={"ok": 5})
print("Vector database initialized and retriever is prepared.")Output:
If you’ll be able to see this widget, which means you may obtain the BAAI/bge-small-en-v1.5 domestically.
Step 4: Design the Superior LLM Immediate
That is probably the most vital step. We design a immediate that instructs the LLM to behave as an professional question interpreter. The immediate forces the LLM to observe a strict course of to and return a structured JSON object. This ensures the output is predictable and straightforward to make use of in our software.
Key options of the immediate:
- Clear Function: The LLM is advised it’s an professional system for a grocery retailer.
- Context is Key: It should base its choice on the listing of retrieved merchandise.
- Obligatory JSON Output: We instruct it to return a JSON object with a selected schema: corrected_query, identified_product, confidence, and reasoning. That is essential for system reliability.
from langchain_groq import ChatGroq
from langchain_core.prompts import ChatPromptTemplate
# IMPORTANT: Set your Groq API key right here or as an setting variable
os.environ["GROQ_API_KEY"] = "YOUR_API_KEY” # Exchange along with your key
llm = ChatGroq(
temperature=0,
model_name="llama3-8b-8192",
model_kwargs={"response_format": {"kind": "json_object"}},
)
prompt_template = """
You're a world-class search question interpretation engine for a grocery supply service like Zepto.
Your major aim is to grasp the consumer's *intent*, even when their question is misspelled, in a unique language, or makes use of slang.
Analyze the consumer's `RAW QUERY` and the `CONTEXT` of semantically comparable merchandise retrieved from our catalog.
Primarily based on this, decide the almost definitely product the consumer is trying to find.
**INSTRUCTIONS:**
1. Evaluate the `RAW QUERY` towards the product names within the `CONTEXT`.
2. Establish the only finest match from the `CONTEXT`.
3. Generate a clear, corrected search question for that product.
4. Present a confidence rating (Excessive, Medium, Low) and a quick reasoning to your selection.
5. Return a single JSON object with the next schema:
- "corrected_query": A clear, corrected search time period.
- "identified_product": The total identify of the only almost definitely product from the context.
- "confidence": Your confidence within the choice: "Excessive", "Medium", or "Low".
- "reasoning": A short, one-sentence clarification of why you made this selection.
If the question is simply too ambiguous or has no good match within the context, confidence needs to be "Low" and `identified_product` may be `null`.
---
CONTEXT:
{context}
RAW QUERY:
{question}
---
JSON OUTPUT:
"""
immediate = ChatPromptTemplate.from_template(prompt_template)
print("LLM and Immediate Template are configured.")Step 5: Creating the Finish-to-Finish Pipeline
We now chain all of the parts collectively utilizing LangChain Expression Language (LCEL). This creates a seamless movement from question to last consequence.
Pipeline Movement:
- The consumer’s question is handed to the retriever to fetch context.
- The context and unique question are formatted and fed into the immediate.
- The formatted immediate is distributed to the LLM.
- The LLM’s JSON output is parsed right into a Python dictionary.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
"""Codecs the retrieved paperwork for the immediate."""
return "n".be part of([f"- {d.metadata['product_name']}" for d in docs])
# The principle RAG chain
rag_chain = (
format_docs, "question": RunnablePassthrough()
| immediate
| llm
| StrOutputParser()
)
def search_pipeline(question: str):
"""Executes the total search and correction pipeline."""
print(f"n{'='*50}")
print(f"Executing Pipeline for Question: '{question}'")
print(f"{'='*50}")
# --- Stage 1: Semantic Retrieval ---
initial_context = retriever.get_relevant_documents(question)
print("n[Stage 1: Semantic Retrieval]")
print("Discovered the next merchandise for context:")
for doc in initial_context:
print(f" - {doc.metadata['product_name']}")
# --- Stage 2: LLM Correction & Choice ---
print("n[Stage 2: LLM Correction & Selection]")
llm_output_str = rag_chain.invoke(question)
attempt:
llm_output = json.masses(llm_output_str)
print("LLM efficiently parsed the question and returned:")
print(json.dumps(llm_output, indent=2))
corrected_query = llm_output.get('corrected_query', question)
besides (json.JSONDecodeError, AttributeError) as e:
print(f"LLM output didn't parse. Error: {e}")
print(f"Uncooked LLM output: {llm_output_str}")
corrected_query = question # Fallback to unique question
# --- Closing Step: Search with Corrected Question ---
print("n[Final Step: Search with Corrected Query]")
print(f"Looking for the corrected time period: '{corrected_query}'")
final_results = vectorstore.similarity_search(corrected_query, ok=3)
print("nTop 3 Product Outcomes:")
for i, doc in enumerate(final_results):
print(f" {i+1}. {doc.metadata['product_name']} (ID: {doc.metadata['product_id']})")
print(f"{'='*50}n")
print("Finish-to-end search pipeline is prepared.")Step 6: Demonstration & Outcomes
Now, let’s check the system with a wide range of difficult queries to see the way it performs.
# --- Check Case 1: Easy Misspelling ---
search_pipeline("aata")
# --- Check Case 2: Vernacular Time period ---
search_pipeline("kanda")
# --- Check Case 3: Model Title + Misspelling ---
search_pipeline("cococola")
# --- Check Case 4: Ambiguous Question ---
search_pipeline("chese")
# --- Check Case 5: Extremely Ambiguous / Obscure Question ---
search_pipeline("drink")Output:
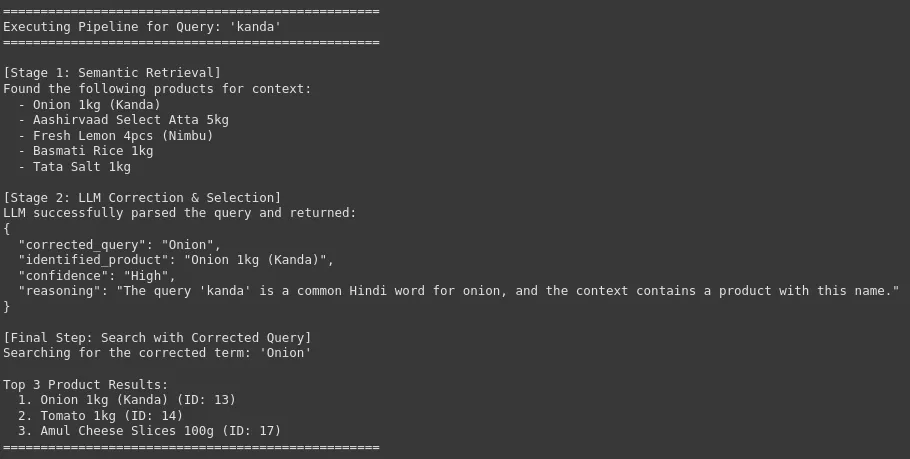
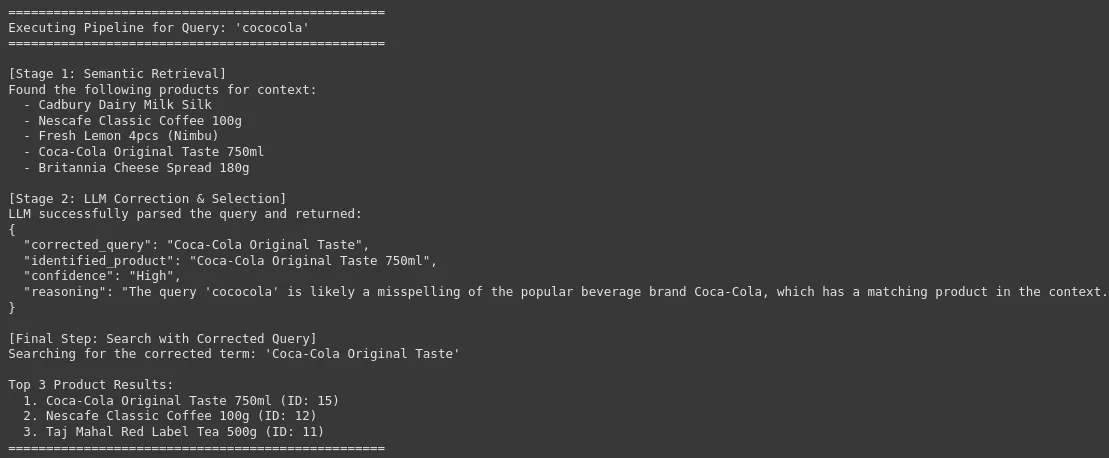
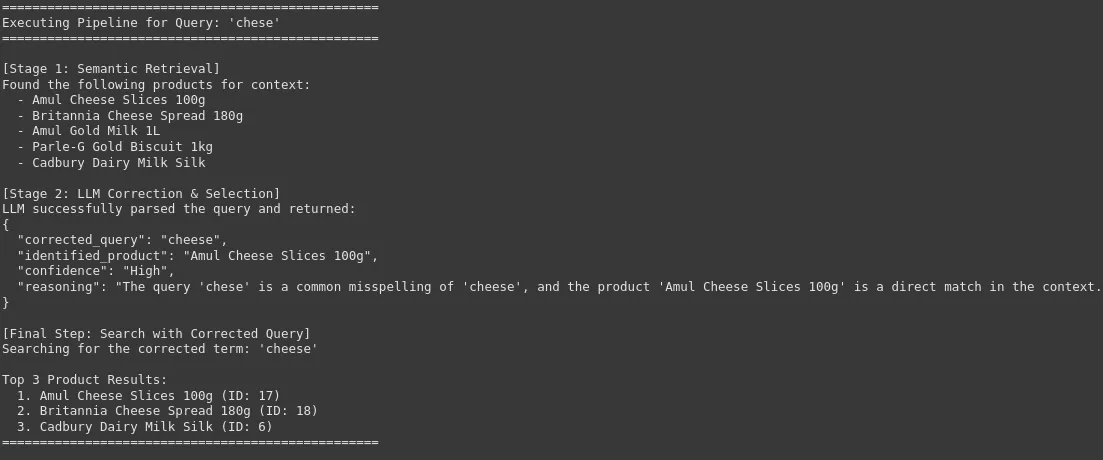
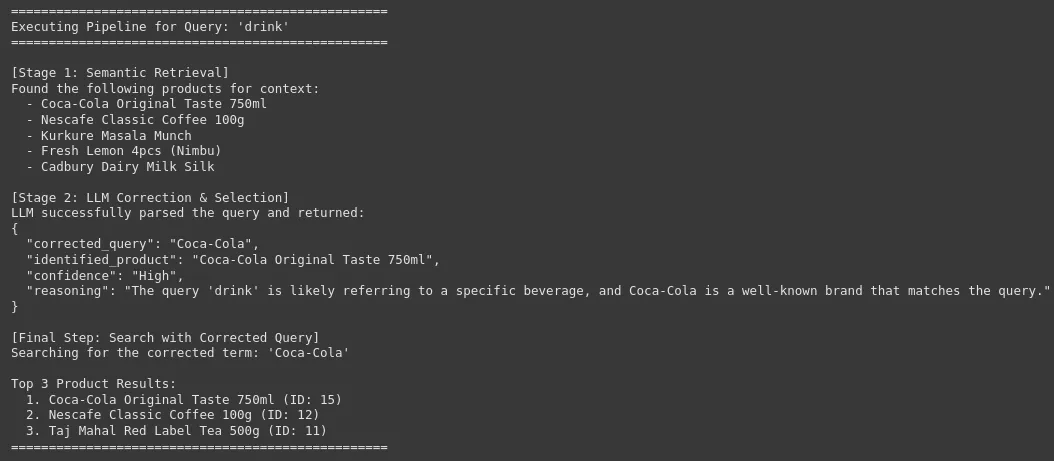
We will see that our system can appropriate the uncooked and noisy consumer question with the precise and corrected model or product identify, which is essential for high-accuracy product search in an e-commerce platform. This results in enchancment in consumer expertise and a excessive conversion charge.
You could find the total code inside this Git repository.
Conclusion
This multilingual question decision system efficiently replicates the core technique of Zepto’s superior search system. By combining quick semantic retrieval with clever LLM-based evaluation, the system can:
- Right misspellings and slang with excessive accuracy.
- Perceive multilingual queries by matching them to the right merchandise.
- Disambiguate queries through the use of retrieved context to deduce consumer intent (e.g., selecting between “cheese slices” and “cheese unfold”).
- Present structured, auditable outputs, exhibiting not simply the correction but additionally the reasoning behind it.
This RAG-based structure is strong, scalable, and demonstrates a transparent path to considerably enhancing consumer expertise and search conversion charges.
Continuously Requested Questions
A. RAG enhances LLM accuracy by anchoring it to actual catalog information, avoiding hallucination and extreme immediate measurement
A. As an alternative of bloating prompts, inject solely the highest related model phrases by way of the retrieval step.
A. A multilingual Sentence‑Transformer mannequin, like BAAI/bge-small-en-v1.5, optimized for semantic similarity, works finest for noisy and vernacular inputs.
I specialise in reviewing and refining AI-driven analysis, technical documentation, and content material associated to rising AI applied sciences. My expertise spans AI mannequin coaching, information evaluation, and knowledge retrieval, permitting me to craft content material that’s each technically correct and accessible.
Login to proceed studying and revel in expert-curated content material.